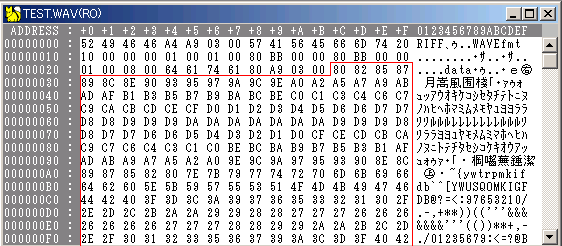
赤枠が音声データなのだが、見てわかるように「単なる数字」でWavファイルの中に棒グラフや折れ線グラフが入っているわけではない。
世の中には「どうしてそんなモノが広まったままなのか理解に苦しむ」ような誤解や勘違いやデマや迷信や都市伝説やヨタやその他諸々が数多くあるが、音楽関連の事柄ではとくに多いような気がする。目に付くものの中から筆者でも説明できそうなものを選んでいくつか紹介する。後半は初心者向けの予備知識的な話もいくつか。
詳しい話は全部すっ飛ばして表面だけなめるので、ちゃんと知りたい人は外部リンクのページから解説サイトを探すなり、専門書を買ってきて読むなりして欲しい。このサイトにももう少し詳しい記事がいくつかあり音楽メモの目次から辿れるが、内容はいい加減である。
トップバッターはなんといってもこれだろう。
たとえばWavファイルの中身(ごく一部)はこんな風になっている(バイナリエディタというソフトを使えば見られるので、手元で試したい人はやってみよう)。
赤枠が音声データなのだが、見てわかるように「単なる数字」でWavファイルの中に棒グラフや折れ線グラフが入っているわけではない。
ためしに最初の4つ分だけ読み取ってみると、このデータは8bit符号なし整数(という情報は赤枠より上の部分に書いてある)なので「128、130、133、135」になる。後でもし仮にグラフを描きたくなったら、この数字が「縦軸の値」になる(横軸の値は時間)。
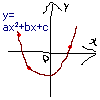
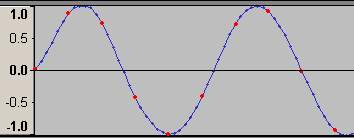
さて・・・「グラフの点」という話になって思い出して欲しいのは学生時代の話である。こんなグラフを描かされた記憶がないだろうか。
実はこれ
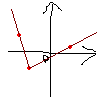
こんな風に繋ぐこともできないわけではない。
学校の授業で上図のような手抜き作図をした場合、威勢がよかった時代の教師が相手ならグーで殴られかねないが、これにはこれなりのメリットがある。グラフの「大まかな形」はだいたい表現できているし、なにより「非常に素早く」描ける(頂点を求めたりそれっぽい線を引いたりという手間をすべて省いているのだから当然)。
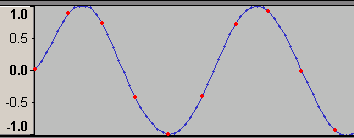
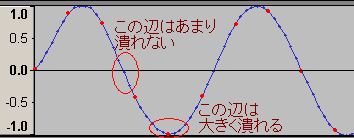
さて、波形編集ソフトでWavに記録された波形を見てみよう。
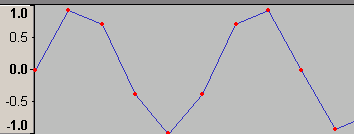
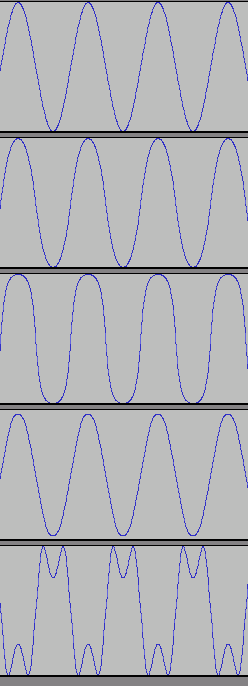
これは32bit-floatの8000Hzサンプリングで1500Hzの正弦波を記録したもの(さっきバイナリエディタで中を覗いたファイルとは別物)。赤い点が「wavファイルに記録されたデータ」で青い線は「わかりやすいようにソフトが引いてくれた線」である。
ほとんどの読者はとっくに気付いていると思うが、これは先ほどの「手抜き作図」と同じ方法で描画されている。理由はもちろん、波形編集ソフトにとってグラフの表示はさほど重要な仕事ではなく、そんなものに手間をかけていると処理が重くなって肝心の音声加工に差し支えるからである。
実際、同じデータを音声として再生する際には
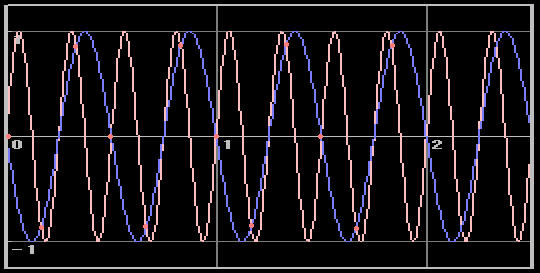
少なくともこのくらいの真面目さで波形を描くことになる。
もちろん、Wavに記録された点のデータからカクカクのグラフを描くことは可能だが、それはなにかメリットがあってあえてやる場合だけである。カクカクのグラフも描けるのとカクカクのグラフしか描けないのはまったく意味が違う。デジタル音声はテンテンなのであってカクカクではない。
前の項の話が理解できていればこれも自然と理解できると思うが、量子化ノイズ(デジタルデータは「ちょうどの値」しか表現できないので、その誤差が生むノイズ)もカクカクではない(あえてカクカクグラフを持ち出して説明している例が多すぎて、呆れる以外にない)。なお「ビット深度」とか「量子化ビット」とか「ビットレート」とか「分解能」とか「ワード長」など字面が異なる表現がいろいろあるが、この項を読む分には、すべて「波形グラフを描くときの縦の細かさ」だと思っておいて差し支えない。
量子化ノイズは通常、最大振幅=1bit幅のランダムノイズで、極小音領域でのみちょっと変わった振る舞いをするのだが、図でやるより音声の方がわかりやすいだろう。同じ元データを8bit(酷い音質なので音楽用には普通使わない)と16bit(CDと同じビット深度)で出力したものを聴き比べてみよう(flacに圧縮してある:再生できない人はNorthern VerseさんのSoundPlayer Lilithなどを利用)。
8bitの方を静かな部屋で再生すると「シュー」というノイズが(とくに小音量になった部分で)聴こえると思う。これが(諸般の事情から今回はデジタルシンセの波形を使ったので「通常の」ものではないのだが)量子化ノイズである。ここで注意して欲しいのは、8bitが16bitになったときに量子化ノイズが半分になるわけではないということである。細かい理屈は省くが、ビットが8増えると量子化ノイズは2の8乗分の1=256分の1になる。
これも詳しいデータは省くが、16bitのWavに乗った量子化ノイズを聴き分けるのは、一般住宅だと(環境ノイズが量子化ノイズより圧倒的に大きいため)逆立ちしても不可能である(こんなファイルを作って非常識なくらい大音量で再生するなら別:実際に試す人は機器や耳を痛めないように注意)。音楽スタジオのエンジニアリングブースのような環境でも、普通に録音されたCDから量子化ノイズを聴き分けるのはまず不可能である(少なくとも、音響関係の研究施設で使っているクラスの設備が必要)。
ただし、データに対して「割り算」や「整数でない掛け算」をやると、たとえば値が「57」だったデータを2で割って「28.5」とか、値が「19」だった波形に3.1をかけて58.9とか、端数が出てくる。これを四捨五入する作業を256回ほど繰り返すと(またまた詳しい経緯は省くが、結局)8bitデータと同じ品質になってしまう(凝った作業をすると、操作が100回200回になることは普通にある)。
一方、たとえば16bit録音したデータを256本くらいミックスする場合はどうかというと、それぞれの録音が普通に行われていればまったく問題にならない。なぜかというと、デジタルデータは音量の最大値が決まっているので、もし256本のデータをミックスするなら、平均で256分の1くらいに音量を下げてから混ぜるはずである。このとき量子化ノイズの音量も256分の1になって、それがまた256個分集まるわけだから問題になりようがない。たとえ0dbFSの256分の1(約-48dbFS)くらいのごく小さい音量で録音したデータを256個単純加算するのであっても、シグナルとノイズが256個分集まるだけなのは変わらず、S/Nは変化しない(というか、もともとあったシグナルの合計とノイズの合計の「比」だけに左右される:割り算の順番など処理方法で微妙な差は出るが、普通にやっていればまったく無視できる)。
まとめよう。デジタル音声を編集する場合は、24bitとか32bitなどでやった方がよい(32bitでやれば1万回や2万回の操作はどうということがないし、整数データ同士なら、ビット数を増やす変換はまったく自由に行える:2分の1を4分の2と書き換えても値が変わらないのと一緒)。デジタル音声を録音/再生する場合は、16ビットもあれば十分余る。なお、ハイビットレートでの編集を行うために必要なのはハイビットレート対応の編集ソフトorハード(たとえばAudacityやReaper0.999は32bit編集に対応している)であって、ハイビットレート対応のサウンドカードは必要ない。
このネタもう疲れてきたな・・・。とりあえずこれで最後。まずはサンプリングノイズと「デジタルデータは時間が飛び飛びなので、間が云々」という話の関係から紹介しなくてはならない。なお、以下では「サンプルレート」という語を用いているが「サンプリング周波数」と同義なので読み替えてもよい(「波形グラフを描くときの横の細かさ」を示す)。
もう一度この図を見て欲しい。
点が3つしかないがグラフは描けている。いまさら筆者が説明するまでもないが、2次関数のグラフを描くために必要な点は3つで、それ以上は必要ない(3点わかっていれば後の点は計算でいくらでも増やせるし、もし計算を無限に繰り返すことが(実際には不可能だが)可能なら点を増やしまくって「完全な線」にできる)。
これと似た事情が音声データにもあてはまり、音の波形を記録するために必要な点の数というのは最初から決まっている。いくつあればいいのかというと「記録したい最高音の周波数の2倍(よりほんのわずかでも多く)」あればよい(アナログ音声の録音とデジタルシンセからの直接記録でちょっと事情が異なるのだがここでは無視、横軸は等間隔だという前提)。
なお「アップコンバート(高いサンプルレートに変換すること:アップサンプリングとも呼ばれる)で音がよくなる」というメンドクサイ主張をする人たちがいるのだが、これは図で説明した方が早そうだ。だいたい「デジタル画像のアップコンバート」が引き合いに出されて「画像がこんなに滑らかになったのと同じく、音声データもアップコンバートで云々」と説明される例が多いが、デジタル画像でいうアップコンバートというのは

こんな感じの「表現」を

こんな風に変更してやることで、ほとんどの読者が察しているであろう通り、やっていることは
こんなつなぎ方だったのを
真面目につなぎ直した作業となんら変わりない(というか、下のグラフは上のグラフをアップコンバートしたものである)。つなぎ直しの手段としてたまたまアップコンバートという方法を使っているだけで、デジタル音声を再生する手順としてはごく当たり前の話、つまり、アップコンバートすると音がよくなるのではなくグラフをつなぎ直さないとマトモに音が出ないだけである(とくに、最近よく見るメガヘルツオーダーまでアップコンバートしてから処理するタイプのDAコンバータなら、前段にたかだか数倍のアップコンバータを差し込んだところで意味はない)。
じゃあサンプリングノイズというのは一体なんなのかというと、電子(サンプリングの前に音声を電気に変換するのが普通で、そのための装置をマイクロフォンまたはピックアップという)の量子的振舞いによるもので、普通に音を扱っている分には気にしなくて問題ない。
量子化ビットは比較的自由に使い分けができる(16bitあればまず問題はなく、S/PDIFのデフォルトである20bitやオプションの24bit、パソコンでの処理を高速化するための32bitなども、必要に応じて好きに使えばよい)が、サンプルレートは扱いがやや面倒である。
深いビット深度が要求される場面(デジタル編集を繰り返す場合)があったのと同様、ハイサンプルレートが有効な場面というのもある。が、その前にエイリアシングノイズ(折り返し雑音)というものを知っておかねばならない。
デジタルデータの数について「記録したい最高周波数の2倍」あればよいということを前の項で紹介した。もしなにかの都合でこれをオーバーしてしまったらどうなるだろうか。たとえば1秒間に6点しかデータを取っていない(3Hzまでしか記録できない)のに4Hzの波形が混入してしまった場合、以下のようになる(赤い点がサンプリングしたデータ)。
記録しているのは赤線の波形(4Hz)なのだが、サンプリング回数の都合で青線の波形(2Hz)と区別がつかない(1秒間のデータ数をa、混入した周波数をb、取り違えられる周波数をxとするとx = a - bになる:上の例では6引く4で2)。
この「取り違えられた音」がエイリアシングノイズ。アナログ音声をデジタル化して記録する場合には普通、サンプリングの前にローパスフィルタ(高い周波数を遮断して低い周波数だけ通すフィルタ)を入れて対策している。問題なのはデータが「最初からデジタル」だった場合、つまりデジタルシンセを設計する場合である(ただ使う分には、設計した人が対策を考えてくれているはずなので気にしなくてよい)。とくに矩形波や鋸波など、倍音が豊富に含まれている波形で問題になる。
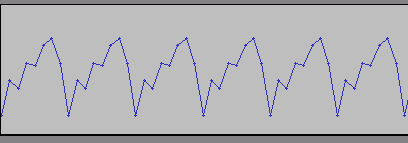
デジタルシンセで矩形波を真面目に(つまり、1倍音、3倍音、5倍音・・・と何度も足し算して)合成すると、

こんな感じの「フチが微妙に波打った」波形になるはずである。実際にこの方法で矩形波を出力するシンセもある(というか、上図はピストンボイスというデジタルシンセの画面)。
しかし、ソフトウェアでそういう実装をすると、動作が非常に重くなる(1つの音色に30も40も波形を使うのだから当然)。一方ハードウェアでの実装、たとえばドローバーオルガンのトーンホイールみたいなものなら、動かしっぱなしにしておいて必要に応じてスイッチを繋ぐだけなので素早く処理できる(電子部品で相当品を作ることも可能:12音/octで10オクターブ用意したとしても120あれば足りるので、専用ハードの用意さえできれば妥当な方法)。
ソフトウェア処理でもう少し上手くやる方法ももちろんある。ひとつはフーリエ変換を利用したもので、Band Limited Impulse Train(BLIT:詳しくはオリジナルの論文なり専門家の解説なりを参照)などがその例。ただし(筆者はちゃんと理解していないが、フーリエ変換する以上は多分)計算量と精度のトレードオフや応答時間の問題がある(はず)。
やっと本論にたどり着いたが、別の方法としてサンプルレートを上げてしまう手もある。たとえば8KHzサンプリングで1KHzの鋸波を出力したい場合、1KHzの音、2分の1の強さの2KHzの音(2倍音)、3分の1の強さの3KHzの音(3倍音)、4分の1の強さの4KHzの音(4倍音)を真面目に重ねるとだいたいこんな波形になる。
ガタガタしているように感じるかもしれないが、4倍音(4KHz)までしか重ねないときの波形としてはこちらが正しい。縮尺や線のつなぎ方が異なるが、ピストンコラージュの画面だとこんな感じになる。
しかし、何度も述べているようにこの波形を出力するのはちょっと手間である。できれば
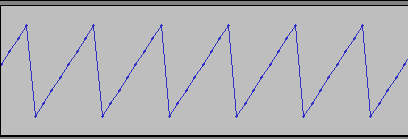
こんな感じの規則正しいデータ(を扱うのはコンピュータを使う場合非常にラク)で済ませたいのだが、これは「ローパスをかけずにデジタル記録した」波形と同じで、折り返しノイズが「豊富に」含まれている(ノイズは、3KHzに化けた本来5KHzの成分、2KHzに化けた本来6KHzの成分、1KHzに化けた本来7KHzの成分・・・と、だんだん弱くなりながら無限に往復する)。
ここでサンプルレートを4倍(32KHz)に上げてみよう。そうすると16倍音(16KHz)までは平和に記録できる。のみならず、記録した「後で」(直交ミラーフィルタのような鋭い)フィルタにかけ、4KHzより上をバッサリ切ってしまえば、折り返してきた27倍音(当然27KHzだが、5KHzに化ける)まではほぼ無視できる。また28倍音以降は音量が非常に小さい。
ようするに、とりあえずノイズ垂れ流しで音を出して、高域に余裕がある形式で記録して、後からバッサリ切ってやればノイズが気にならないねと、そういう話である。しかも、単純なノイズ垂れ流しの場合と比べて、処理の重さは(上の例なら)4倍にしかならない。コストパフォーマンスはかなり良好といえる。
実際の音楽制作では、たとえば48KHzの最終出力に対して一部区間だけ192KHzベースにする、といった方法が考えられる。この場合、フィルタを通した後の処理や記録は48KHzより高いサンプルレートでやっても意味がなく、副作用としてデジタルシンセの出力以外の処理もローパスをかけてリサンプリングするまでの区間ですべて4倍の重さになるため、オシレータ(波形を作る部分)だけサンプルレートを上げるのが効率的(48KHz出力で最終段に20KHzのローパスがかかるなら、モジュレーションなどの影響はほぼ無視できる)。
ここまでに挙げた方法とはさらに別の解決策として、高域の音だけ真面目に出力するという案もある。上の例でいえば出力は4倍音まであればOKなわけで、どうせ「重さ4倍」なら素直に波形を4つ重ねてもよいわけである。低域の音なら折り返すまでにかなりの減衰があるため、さほど気にしなくて済む場合が多い(軽い動作で有名なsynth1は、これに近い発想で対策をしているようだ)。
ちゃんとした説明がほとんどなされていないが、デジタルケーブルにハイサンプルレート信号(たとえば192KHzとか)を通すのは、デメリットばかりでメリットがない。ノンリニアのデータ受け渡しや機器の内部処理、PCIeのように音声信号よりもはるかにハイレートなバスに乗せる場合には帯域を無駄食いするくらいの悪影響しかないが、S/PDIFのような形式でデータ伝送を行う場合、1クロックあたりの時間が短くなってジッタが増えるし、ケーブル長と波長の比が大きくなってインピーダンス整合がシビアになるし、クロックあたりの電力量が小さくなって外来ノイズによるエラーも増える。
ただし、エラーが増えても可聴域に問題が出ない可能性はあるし、ハイサンプルレートでビットパーフェクトな(=ノーエラーの)伝送が可能なシステムも(値段が無駄に高く取り回しが不自由なだけで)普通にある。スタジオユース前提の機材にこういった仕様のものが多いのは、ホームユースとは予算の桁が違ったり専用に配線工事を行えたりといった事情があるため(2011年現在も(DVD-Audioはフェードアウトしたようだが)SACDが細々と生き残っており「なんでスペックを使い切らないんだ」というゴムタイなクレームに晒されないための対策として必要、という事情ももしかしたらあるのかもしれないが、筆者の知ったことではない)。
これだけ問題が増える一方で、メリットはまるでない。スピーカから超音波を出すのが好きな人もいるようだが、だったらディスプレイにも紫外線発生装置をつければよさそうなものである。紫外線も出して目の疲れまで再現しないと忠実な画像ではないとか、超音波も出ないと忠実な音声でないという主張の人が、自分の健康を犠牲にして「高画質」や「高音質」を楽しむのは、止められるものなら止めた方がよいのかもしれないが、多分言っても聞かないだろう(赤外線や低周波を出そうという試みなら、ある程度は理解できる:焚き火を映し出したら熱も届くディスプレイとか、かなり危険な気もするが面白そう)。
サンプルレート変換で使うローパス/ハイカットフィルタの影響を避けるうえで有効だという主張も目にする。理想的なフィルタ(窓関数を掛けないsinc関数)でローパスさせることが不可能な以上、影響が100%ないとは言い切れないのだが、言い切れないだけで実用上は問題がない(フィルタについてはかつのへやというサイトの解説が詳しい)。FFTにかけたとき実時間あたりの情報量が増えるというのは事実だが、その「増える情報」というのは「超音波域のスペクトル分布」に関するものなので、実用上の意味はない(非実用的な使い道なら、超音波域にspectrogram artを仕込むとか、ムリヤリ捻り出せなくはない)。
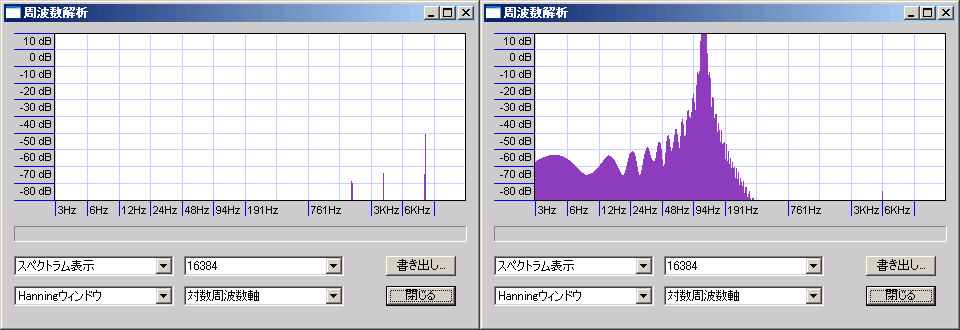
なおサンプルレートが上がると同じ窓に対する時間が短くなるため、観測対象周波数が同じなら計算量に対するFFTの精度が下がる。下図は-40dbFS10秒間100Hzの正弦波にスペアナをかけたもの(横の縮尺が違うので見た目よりも差が大きいことに注意)。
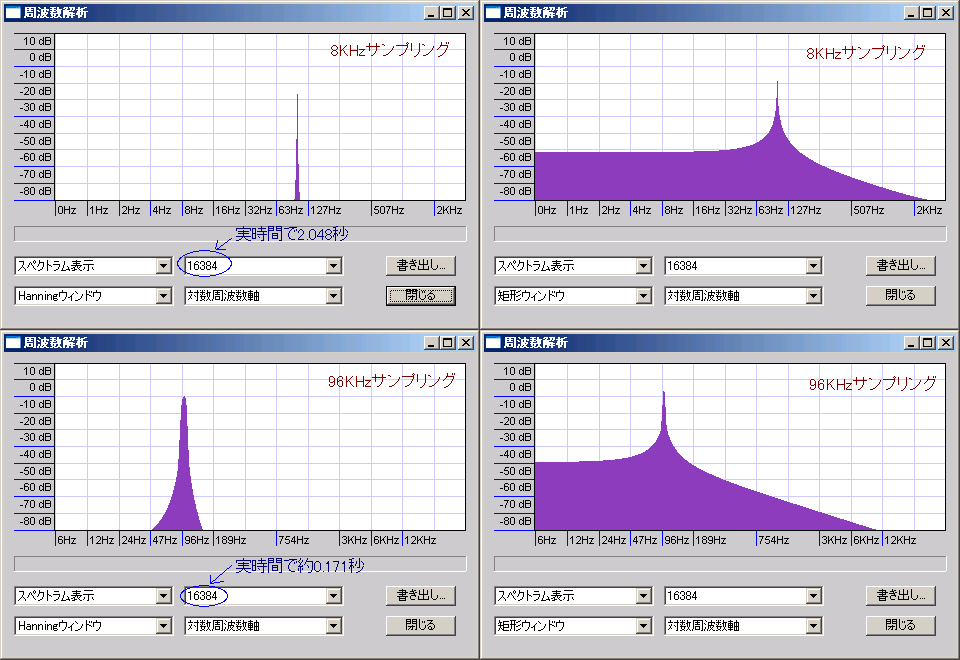
もちろん、サンプルレートを上げただけ窓も大きくすれば精度は保てるが、計算量が大きく増加する。
位相領域の情報量が増えるというのも変な話だが、説明がややこしくなるので実際の波形を紹介してお茶を濁そう。こんな風に位相がずれた波形(2000Hzの信号を48000Hzサンプリングして2サンプルづつずらしているので、初期位相ゼロ、pi/6遅れ、pi/3遅れ、pi/2遅れに相当)を
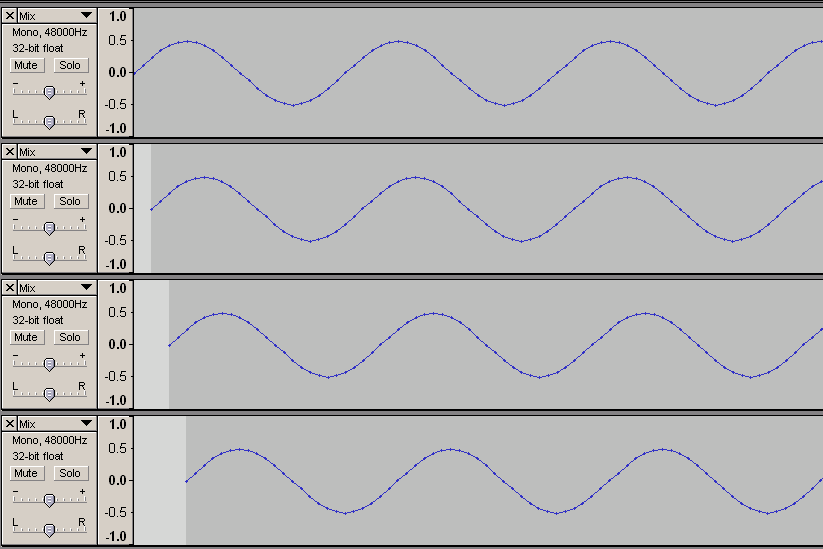
8000Hzサンプリングで「記録」しても
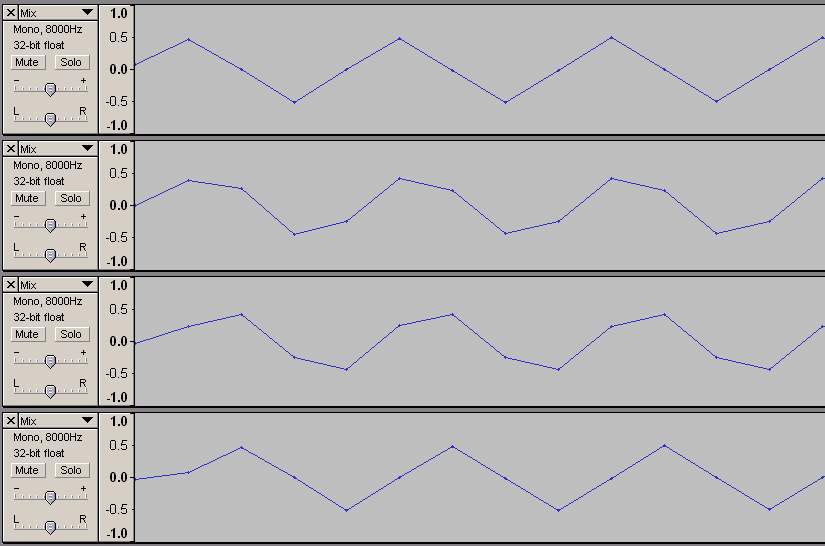
あとで位相に関する情報を引き出すことに支障はない(下図では48000Hzサンプリングにアップコンバートして情報を取り出した)。
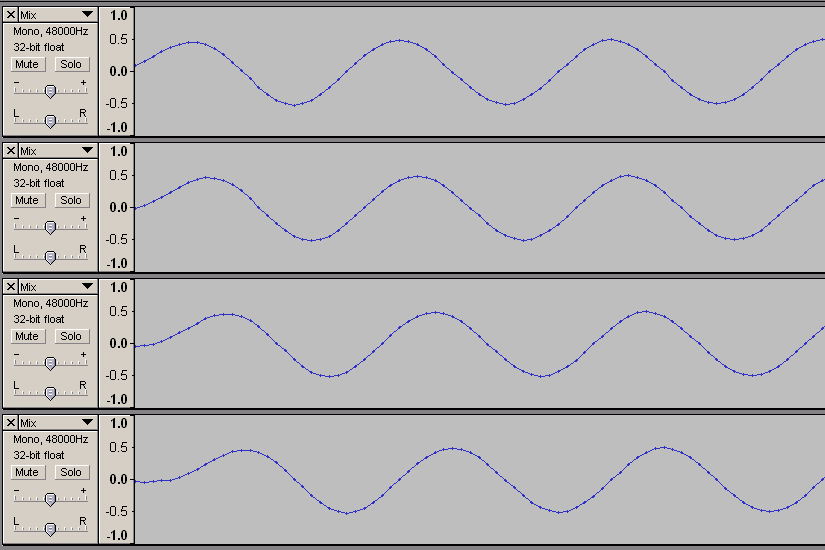
波形の最初がちょっと乱れているのは、存在しないデータを推測で補ったため。また最初にサンプリングする時点では、ある程度高いレートでサンプルを採取しないと情報を取り逃す(普通のA/Dコンバータなら、メガヘルツオーダーのとんでもないハイレートで変換しているので問題にならない)。真ん中の図では波形が歪んでいるように見えるかもしれないが、何度も紹介したように、処理の高速さを優先しあえて情報を取り出していないだけで、振幅や位相に関する情報はちゃんと記録されていて、適切に処理すればいつでも取り出すことができる。
なお、超音波が耳(やその他の器官)の健康にどの程度の影響を与え得るのか、筆者は詳しいことを知らないし、影響を確実に予言できる人もいないだろうと思う(筆者自身は、医学検査などで必要に迫られない限り、わざわざ耳に入れたいとは思わない:まあ意図的に流さなくても生活環境で普通に暴露していそうではあるので、それほどムキになるようなものではないのかもしれない)。2019年追記:超音波への暴露が起こす生理的ないし心理的効果(ハイパーソニック・エフェクトと総称される)は2000年代にいくつか取りざたされ、ガムラン(バリ島の民族楽器)など超音波成分が豊富な音色が基幹脳などの活性を高めるというデータが示されている。ただし超音波成分単独では効果がなく、また受容器官は耳ではないことがはっきりしている(ヘッドフォンやイヤフォン単独では無意味)。ピアノやオーケストラなど西洋楽器にはハイパーソニック・エフェクトを起こすほどの超音波成分が含まれていない(チェンバロや尺八などにはある程度含まれる)ことも明らかになっており、サウンドスケープのような用途以外には関係しないが、しかし超音波への暴露がヒトになにかしらの作用を及ぼすのは間違いないようである(んなこと言ったら紫外線だって生理的作用は及ぼすけどね)。さらに余談を引き伸ばすと、マイクロ波(wikipediaJPによると「少なくとも200メガヘルツから3ギガヘルツ」らしい)に聴覚効果があることもかなり古くから知られており、1961年のアランフレイによる実験にちなんでフレイ効果とも呼ばれる。80年代くらいからアメリカなどで軍事利用が試みられたほか、害鳥避けへの応用も検討されたことがあるそうな。
他のページでも何度か触れているが、ハウリングが起き得る環境(PAや放送はもちろん、音声編集でもルーティングミスでハウリングが起きる可能性はゼロではない)で可聴域外の高音をタレ流したままモニタするのは危険である。とくにデジタル環境では「0dbFSで発振する」可能性を必ず検討しておかなければならない。
通常のハウリング以外に、シンセの誤設定やハードorソフトのバグや誤操作や誤設定などでも異常な出力は生じ得るし、アナログ回路が超音波域のノイズ(あり得そうなソースとしては、現在主流のスイッチング式ACアダプタを音響機器に使って小電流を得た場合の電源ノイズなど)を拾う可能性もあればアナログアンプの複数つなぎ(とくにオーバードライブorディストーション>ハイゲインアンプなどの接続)で電気的に発振することもあるし、変則的な接続だとクロストーク(漏話)で回路が繋がってフィードバック発振する可能性もある。
可聴域の大音量なら、反射的にヘッドフォンを外したりボリュームを絞ったり、あるいはモニタスピーカから顔を背けたりといった反応がたいていはできる(もちろん、耳を傷める危険があることに変わりはない)が、可聴域外の音だと、少なくとも一瞬は反応が遅れることになるだろう。
実際問題、可聴域外の高音だけが大音量再生される可能性が高いとは思わないが、それでも、万が一そういう事態が生じた場合のリスクを考えると、無視できるような問題ではない。フィードバックの一部に空気を介した音波の伝達が噛んでいる場合、ディレイタイムのわずかな変化で合算時の位相関係が変わり、断続的な異常出力が起きやすいのもタチが悪い。プロ用の製品ならともかく、一般向けにハイサンプルレートのモニタ機能が付いた機器を販売しているメーカーやベンダーには、責任をもって注意喚起を行うようぜひお願いしたい。
ユーザー側での自衛手段としては、不要な帯域はフィルタなどで遮断しておくことがまず挙げられる。また、ハードウェアセッティングを工夫して限界音量自体を安全なレベルに近付けておくことも対策になるだろう。とくにデジタル区画では、知覚できない超音波を0dbFSで再生できること自体が危険なのだという認識をぜひ持っておきたい。
これもまた「超音波を」という表現が面倒なのだが、なんらかの超音波源があってその出力(というか音量)が変化するとき、それを知覚することができないわけではない。おもに2つのメカニズムによる。
ひとつは歪みによるもので、処理方法にもよるが普通に音量を変化させると波形が歪む。
上図は10KHzと120Hzの正弦波に5Hzくらいのトレモロをかけた波形の周波数成分で、元の波形よりも低い周波数に歪み成分が生じているのがわかる(トレモロの仕様、元の周波数、トレモロの周波数などで歪み方が変わる)。超音波自体は知覚できなくても、超音波を歪ませた歪み成分が可聴域にあれば知覚できる。この歪みはトレモロで波形が変わるから生じるもので、
図の上の波形のように1周期ごとに音量を変えてやれば歪まない(が、狙ってやらなければこんな変化になることはまずない:特殊なデジタルシンセを設計するときに使えなくもないかもしれず、どうせやるならサイン波ではなくコサイン波でやった方が曲率の問題などがスッキリするかもしれない)。
この成分は可聴域の実音なので、超音波を記録再生しなくても反映することができる。またもちろん、トレモロ以外にも分数倍音的な歪みを生じる処理はあり、たとえばアンプのクロスオーバー歪みなどでも本来の成分より低い周波数が検出されることがある。
もうひとつは包絡線検波に似たもので、パラメトリックスピーカという機器に応用されている。超音波に可聴域の波形で変調をかけてやることで、
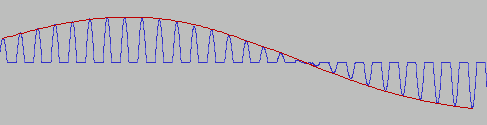
青線が本来の波形(超音波)なのだが、人間の耳がついていけず赤線のように知覚されるというものである(実機のパラメトリックスピーカがどのようなキャリアを使っているのか、整流がどうなっているのかも知らないので、あくまで想像図:というか使い回しの画像)。
上記に近い作用が起きる可能性としては、プラス領域とマイナス領域で非対称な歪み方をするディストーションイフェクトにより、倍音成分のぶつかり合い(による音量のうなり)と擬似的な整流効果が生じたときくらいだろうか(いくら超音波が出ていても、ちゃんと整流しなければパラメトリックスピーカと同様の効果にはならないはず)。
この成分は可聴域の実音でないが、ローパス(ただし仕様は吟味しなければならない)をかけてやれば勝手に可聴域に繰り入れられる(やっていることはデジタルアンプの出力段のローパスと同じ)わけで、レコーディング~マスタリングまでのどこかで適切に処理してやれば、やはり超音波を記録再生する必要はない。
これもデジタルシンセを設計する人以外は気にする必要がない話。ループが長い純音を出力してからスプライン補間など長いループに弱い処理を後段に入れると意図せず音が歪むことがあるので、どのような挙動を示すかあらかじめ確認しておこう。
サンプルレートの半分(これをナイキスト周波数と呼ぶ)から見て何分の1かと考えたときの分母が大きいと、波形がループするまでの時間が増える。たとえばナイキスト周波数の20分の19倍(=95%)の音だと20サンプルで1ループになり、8000Hzサンプリングで3800Hzの音だと0.0025秒、48KHzサンプリングで22800Hzの音だと0.0004167秒かかる。もっと微妙に51/100あたりだと100サンプル必要で、8000Hzサンプリングで2040Hzの音だと0.0125秒、48KHzサンプリングで12240Hzの音だと0.002083秒かかる。また無理数倍の場合は基本的にループしない(しなくても普通の録音再生には問題ない)。
普通の録音やリスニングには影響がないはずだが、もしどうしても影響が心配な人は、カセットテープやアナログMTRやアナログレコードなどなど「間にデジタルが入らない形式」で録音した音声を、ラインアウトやヘッドフォンアウトなどからそのままアナログ出力した音と、パソコンやデジタルアンプやデジタルミキサなどデジタル形式が間に入る機器を噛ませた場合で、変化があるかどうか試してみればよい。
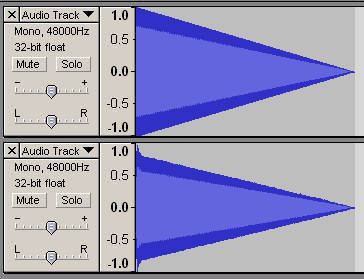
何度も繰り返していることだが、音声データを非可逆圧縮(=mp3やOgg VorbisやAACなどに変換)すると音量が変わる。この図をもう1度見てみよう。
赤枠がデータで、最初の4つが「128、130、133、135」を示しているのだった。
で、非可逆圧縮とは「元と完全に同じくはならない」圧縮方式、つまり「データが変わる」加工である。音声データは数値で記録されるのだから、データが変わるといったら「増えるか減るか」のどちらかしかない。つまり、たとえば「128」だったデータが「127」とか「129」などに変化してしまうということである。
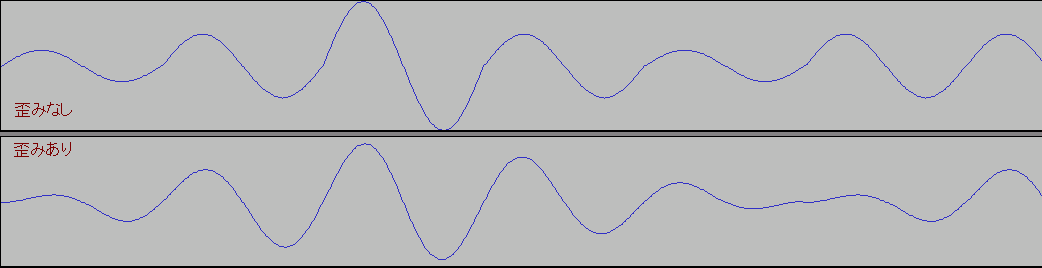
ぶっちゃけ微妙な変わり方なので聴覚上ほとんど問題はない(からこそ非可逆圧縮が利用されている)のだが、圧縮の影響で「最大音量」を突っ切ってデータが変化することがあるので音量オーバーには気をつけましょうと、単にそれだけの話である。一応、編集などのページで使用した図を再掲しておく。

上が圧縮前で下が圧縮後。
音量変化がとくに出やすいデータ(キラーソースという)をわざわざ選んで実験しているため、実用上はここまで激しく波形が暴れることはない(ただしシンセなどでホワイトノイズ系の音色を使っている場合には注意)が、どの程度暴れるかは圧縮してみないとわからないため、音量オーバーが嫌いな人は多めに余裕をとっておけばよい。
なお非可逆圧縮とはいっても、実用上の影響は高音が切れるくらいで、それ以外の音はほとんど変わらない(単独の破裂音など、非可逆圧縮に弱いデータを選んで強く圧縮すれば、プリエコーやリンギングなどの顕著なノイズを生じさせることは可能:これらの「信号処理に由来する顕著なノイズ」はとくにアーティファクトと呼ばれ、動画のブロックノイズなんかもアーティファクトの仲間)。中低域中心のデータとそれを圧縮したしたものの比較用サンプル(リンク先の「guitar」で始まるファイル名のもの)を再掲しておく。ただし、何度も繰り返すとさすがに劣化が耳につくので、圧縮回数はできるだけ減らそう(Waveを1回だけ圧縮したファイルとその後mp3をWaveに戻してまた圧縮する作業を5回繰り返したファイルも再掲しておく)。
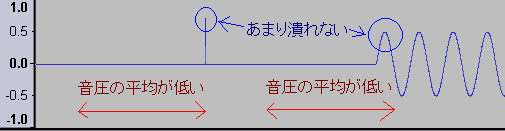
「音量が変わる」と言い切るとちょっと語弊があるのだが、もう少し正確に言うと、デジタルデータとしてのピーク音量が変わる。
またまたこの図を見てみよう。
図中で「一番下にある赤点」は真ん中の点だが「線が一番低い場所」はもっと低い。もし点の位置が変わったら(または単純に点が増えたら)「一番高い点」や「一番低い点」が変わる可能性がありますねと、そういう話である。
これも前の項と同様、普通に作業する分には気にするような問題ではないが、元の音量が最大ギリギリだと音量オーバーすることがあるので注意しておこう。ネットで不特定多数に配布するファイルでは、リサンプリングはかかるものと思っておいた方がよい。やはり、どの程度ピーク音量が変わるかはリサンプリングしてみないとわからないため、音量オーバーが嫌いな人は多めに余裕をとっておけばよい。
とくに、インテルのAudio Codec 97(AC'97)という規格に準拠したサウンドデバイスで48000Hzサンプリングでないデジタル音声を普通に再生すると、強制的にリサンプリングされてしまう(もちろん、この規格に準拠していなくても同様の処理を行うソフトやハードはある)。2004年に策定された後継のHigh Definition Audio(HD Audio)という規格でもなかなか楽しげな仕様(詳しくは公式ドキュメントのFigure 3とそれに続く説明を参照)になっており、普及率も圧倒的なので、パソコンでの無難な再生を望むなら48000Hzでサンプリングしておくのがよいだろう。
なおリサンプリングも誤差を排除できない(計算量を無限大にできればいいのだが、現実にはムリなので適当なところで打ち切る)操作で、たとえば同じ44100Hzから48000Hzへのリサンプリングだったとしても、作業環境によって結果は微妙に異なる(Audacityのように、忙しいときとヒマなときでリサンプリングのやり方を変えるソフトもある:このため、どの機器をどのモードで使ってリサンプリングするのか事前にわかっていないと、リサンプリング後の波形を正確に知ることはできない)が、この影響も普通に録音再生をやっている分には気にしなくて大丈夫。
さらに余談を引き伸ばすと、サンプル間ピーク検出型のマキシマイザーをやたらと持ち上げる人もいるようだが、あれはそれほど万能なものではない。たとえば(M系列符号などの)1ビット相当ランダムノイズをサンプル間ピークが0dbFSを超えないように加工し、さらにいくらかマイナスの増幅をかけてから、サイン波がユニティゲインで返ってくることがわかっている処理系でループバックさせてみよう。これは「間違った使い方」なので波形が暴れてもマキシマイザーのせいではなく、録音再生系の誤差(大小の差はあれどゼロではあり得ない)が波形に反映されただけである(マキシマイザーはそこまでの面倒は見てくれない)。どんなに優れた道具も使い方を知らなければ有効には働かないことを心しておきたい(そもそもの話として、サンプリングレートの違う複数の経路で同じマスターを配信したいのでなければ必要ない道具だったりもする:ユーザーの手元で「間違った」アップコンバートがなされたときの対策にはならないし、アップコンバータを適切に実装すればサンプル間ピークなど問題にならなず、実際筆者の手元のFast Track Ultraは0dbFSの1ビット相当ランダムノイズも「ちゃんと再生」する)。
当たり前すぎてなんともアレだが、リニアフェイズEQは「位相歪みがないフィルタ」であって「歪みがないフィルタ」ではない。
また学生時代の話を思い出して欲しいのだが、地図の描き方で「正距方位図法」とか「正積方位図法」とかいうのを習ったと思う。3次元である地球の形を2次元の地図に変換する際に、距離、方位、面積、角度などのパラメータ全部を正確に表現することができないので「今使いたいパラメータ」が正確になるものを選ぶ、という話だった。ついでにいえば「どれも正確ではないがそこそこ歪まないパラメータが多い」ミラー図法や、複数の図法を部分的に組み合わせたグード図法というのもあった。
デジタル音声に戻って考えると、フィルタをかける際に平坦(あるいは任意)であって欲しいパラメータは、振幅特性、位相特性、過渡特性などいろいろあるが、これらすべてを意のままに操るフィルタは作れない。時間軸での収束の仕方やパワーの密度変化も問題になる。リニアフェイズEQは、その中で位相特性を平坦にしたフィルタである。じゃあリニアフェイズEQはどの辺が不正確なのかというと、これは手元で試してもらった方が早い。この圧縮ファイルの中に、200Hzの正弦波、1000Hzの正弦波、200Hzと1000Hzの和音、200Hzの鋸波、200Hzの矩形波、インパルス波形、ランダムノイズ、1bit相当に潰したランダムノイズが入っている(インパルス波形は-6db、それ以外は-18dbにノーマライズしてある)。
それぞれの波形を普通のEQ(もし持っていなければ、Reaper標準のReaEQか、Audacity用の拙作Nyquistプラグイン(yp_effect)に含まれる「Peaking Equalizer」(PeakEQ.ny)あたり)とリニアフェイズEQ(もし持っていなければ、Aleksey VaneevさんのEssEQやslim slow sliderシリーズのLinearPhaseGraphicEQなど)で加工してから、Audacityなどの波形編集ソフトで出音や波形や周波数スペクトルを(加工前とも比較しながら)確認してみるとよい(200Hzをイジる前提で用意したが、気になる人は他の周波数も試してみよう:ついでに、6db持ち上げてから6db削るなど元に戻す系の処理や、トラック全体ではなく波形の一部だけにかけるパターン、MIDI制御やオートメーションなどEQの設定を動かす場合などでも試してみるとよい)。
さて、読者の手元のEQの特性はどうだったろうか。繰り返しになるが、フィルタは「今必要なパラメータ」をうまくコントロールできるように選ばなくてはならない。ではリニアフェイズEQが必要なのはどんな場面かというと、マキシマイザー用のマルチバンドコンプを設計する場合(ノンリニア編集でピーク音圧をコントロールする目的なのだから、ピーク音圧値が読めるフィルタを使う)である。上記以外の使い方は筆者にはぱっと思いつかない(普段リニアフェイズEQなんて使ってないし:というか、リニアフェイズでなくても普通の使い方なら実用上の問題が出るほどはずれない)が、道具の使い道なんてものは結局発想次第なので、自分が使っている道具の特性と自分が欲しい音をよく理解して、有効な使い道を探して欲しい。
追記:もう一度繰り返しておこう。リニアフェイズEQは決して「ダメなEQ」ではないし、他のEQがいつでもリニアフェイズEQよりよい結果を返すわけでももちろんない。どんな道具も、仕組み(までは大変だとしても、典型的な波形にかけたときの挙動くらいは)を理解しないで使おうとすると「ダメな使い方」になることがあるというだけである。
これも似たような話ではあるのだが、RMSというのは「平均値」の一種である。正確には「2乗して平均した平方根」なのだが、わざわざ「2乗して平方根」を取るのは電力が問題だからである・・・と始めると専門用語がたくさん出てくるので、もう少しぶっちゃけた(しかし不正確な)説明でお茶を濁したい。
深く考えなくても、交流にはプラスとマイナスがあるので、単純に平均を取るとゼロに近い値になってしまうことはわかると思う。何度も使っているこの図に「プラスマイナスゼロ」の線を引いてみよう。筆者の画像加工がズボラで多少点がズレているのは気にしないで欲しい。
2乗して平方根を取るのなら、電圧がマイナスになった部分もムリなく考慮できる。
2乗して平方根を取る理由はとりあえずわかったが、問題はそこではなく「平均」の方である。ピークコンプレッサとRMSコンプレッサの根本的な違いは、前者が「ある時点(普通は現在から一定時間前)の音圧」を基準にするのに対し、後者が「ある時点から一定時間後までの範囲の音圧の平均値」を基準にする点にある。
リリース(とアタック)が極端に短いピークコンプレッサをかけると波形が歪む(=矩形波に近い波形になって倍音成分が発生する)。
この歪みはオーバードライブの歪みと似ており、ピークコンプのアタックとリリースをゼロに設定するとほとんどオーバードライブとして動作する(というか、バスドラムなどではコンプでオーバードライブの代用をすることがある:詳しくはAucacity関連のちょっと変わった使い方のページを参照)。
これに対しRMSコンプでは平均値を元にするため、潰れ方の小刻みな変化が抑えられ、波形が歪みにくい(単純に音量を絞ったのと近い結果になる)。つまり、この2つの根本的な差異は音色なのだが、RMSにはもう少し注意が必要である。
問題になるのは時間的な応答で、平均を取る「区間」を長くすると音量変化への追従性が悪くなる(音量が大きくなってからそれが平均に反映されるまでに時間がかかる)。
かといって区間を短くしすぎるとピークコンプの動作に近くなる(最低でもサンプル2つ分は取らないとRMSにする意味がない)。ノンリニアであれば先読み(アタックタイムをマイナスにする)という手もあるのだが、バッファが必要なのでリアルタイム加工との相性が悪く、頭の問題を尻に回すだけなので根本的な解決ではない。
結局どっちを使うのがいいかといえば、当たり前の話だが「元音」と「欲しい音」次第である。F_S_compのようにピーク/区間の短いRMS/区間の長いRMSでモードを変えられるコンプもあれば、sc4のようにピーク値とRMS値の比重を自由に変えられるコンプもあるし、BLOCKFISHのように自動でやってくれるものもある。また、RMSの区間をかなり短くしておくことで、低音主体の元音と高音主体の元音で歪み方を変えることもできる(副作用で、低音と高音が混じっている場合にコンプの効きがフラつくため、ローカットした信号をキーインにするコンプもある:リリースタイムの設定でも対策できる)。
なお、RMSを計算する際にグラフのつなぎ直しを行うことがあり(というか普通つなぎ直す)、原則として計算量を増やせば増やすほど精度が上がる(無限大にできればピッタリ正確なRMSを求められるが、実際にはムリなのでどこかで打ち切る=ある程度の誤差が出る)。
「アンプ」という言葉はもともと「音を大きくする機械」を指し、実際上は「音量を変化させるハードまたはソフト」のことである。デジタルデータの場合は単純に掛け算をすればよい。アナログ音声は空気の振動(粗密波)でありそのままでは増幅できないため、いったん電気信号に変換してから増幅するのが普通。
なお最初に断っておくと、音量を大きく左右するのはスピーカの能率と指向性とセッティングであって、パワーアンプの出力ワット数は支配的な要素ではない。大型スピーカを駆動するには大出力アンプが必要だという説明もよく目にするが反対で、スピーカは面積が大きければ大きいほど同じ電力で大きな音を出せる(ただし重いと効率が落ちるのでやみくもにサイズアップするのは得策でない)。筆者は丸七のボリュームアンプという機種(単四電池2本駆動、100円)をマーシャルの1960という大型スピーカ(というかギターアンプ用キャビネット)に繋いだことがあるが、普通の集合住宅なら間違いなく近所から苦情が来るくらいの音量は出た。この辺の事情には後でまた触れる。
またスピーカへの入力として1Wというのは相当大きな値で、たとえば6.5インチクラスのモニタ用パッシブスピーカは能率90dBSPL/W@1mくらい(許容入力はせいぜい100~200W:楽器用アンプの大型キャビネットだと100dBSPL/W@1mを超える能率で300Wくらい入れられるものもある)が多く、これを正面1mの距離に2本(=ステレオで)置いて1W+1Wの入力を突っ込むと96dBSPL(同じ音波を2つ重ねると振幅が2倍になる:内訳は、電力2倍で3db+能率(スピーカの面積)2倍で3db=6db)の音圧に晒されることになる(アメリカでは、防音保護具なしの場合、90dbだと最大暴露時間8時間/日、100dbだと最大暴露時間2時間/日という米連邦政府指定基準があり「85dBを超える音に長時間曝される場合は防音保護具の使用が推奨される」:メルクマニュアルより)。また楽器用アンプなどに「ワット数を落とせる」機能が普及してきているが、たとえば10Wの出力を0.1Wに下げると音量が20db落ちる(上の例と同じスピーカなら、正面1mでの音圧が106dbから86dbになる:あくまで、応答がリニアだと仮定した単純計算)。
おもに楽器用アンプで「真空管アンプは同じワット数でも音が大きい」という主張があり、これがまた面倒である。たしかに、真空管アンプは出力が暴れやすく、-1dbドロップポイントやTHDが一定値(1%とか5%とか)になるポイントを定格最大出力とした場合に実際に出力され得るピーク出力との差が大きくなりがちである。スピーカユニットやセパレートアンプのキャビネットを選ぶ場合はそのことに注意を払った方がよい(波高率にも注意が必要で、たとえば正弦波が70Wになるのと同じ振幅で矩形波は100Wを叩き出す)。しかし、楽器用のチューブアンプは歪みやすく作ってあるということを忘れるべきではない。アンプで歪ませるということはヘッドルームがマイナスだということである(しかも、フルチューブであればプリ段とパワー段の両方)。一方トランジスタアンプは歪まないように作るのが普通なので、特殊な使い方をしない限り最大出力いっぱいまでは使わない。このため、似たような出力のアンプヘッドを同じキャビネットに繋いでも、常用音量はかなり異なる(JC-120あたりは本気の最大出力にすると恐ろしい音量になる:カジュアルユース用の耳栓くらいでは耳を守れないくらい危険なので、決して安易に試さないこと)。ようするに、音量オーバーさせてナンボのチューブアンプと比べて、音量オーバーさせないのが基本のトランジスタアンプは大きく余裕をもった設定になっていて、その余裕を使い切ってフルスイングさせると普段の音量とはかけ離れた出力になる(しかも、チューブアンプと比べてコンディションによるパワー落ちが極端に少ない)。
スピーカは振動面積が大きいほど能率が高くなり(単純計算上は比例する)、また数を増やすことでも擬似的に面積を稼げる(ただし波長が十分に長い周波数域のみ)。だいたいの目安として、似たような構成で6.5インチと12インチのスピーカだと5dbくらい、同じスピーカを単発で使うのと2発並列2セット直列で合計4発使うのとでも5dbくらい、それぞれ後者の音量が大きくなる。このため冒頭で挙げたように、小型で出力の小さなアンプでも、マーシャルの1960Vのような能率の高いキャビネットに繋いでやれば音量を稼げる(上の計算に従うと、6.5インチ1発のキャビに10W突っ込むのと同じ音量が、1Wで出る)。「出力の小さなアンプでは大型キャビネットを鳴らし切れない」というのが「最大のキャビネット歪みを得られない」ということであれば間違っていないが、同時に「アンプの出力が小さくても能率の高い大型キャビネットなら補える」ことも覚えておきたい。なお、1960Vというのは10Wも突っ込むととんでもない音量になるキャビネットなので、大出力アンプを使っていても「鳴らし切っている」人はほとんどいないと思われる(カジュアルユース用の耳栓くらいでは到底耳を守れないくらい危険なので、決して安易に試さないこと)。
さて、オーディオ機器が扱う「音声信号の大きさ」はだいたい決まっており「ラインレベル」と呼ばれる。具体的には-10dbV~4dbuくらい(開放端電圧のRMSで0.3~1.2Vくらい:意味がわからない人はとりあえず「0.5ボルトくらい」だと思っておけばよい)。しかし、たとえばマイクの出力は上記よりもかなり小さいのが普通(「マイクレベル」と呼ぶ)だし、デカいスピーカなどを鳴らすには上記では足りない(ヘッドフォンなどはラインレベルの出力を直で突っ込んでやってもたいてい鳴る)。ここまではよいとしよう。
デジタルで増幅する場合、基本的にノイズの増加はない(本当は微妙~~~にあるのだが、実用上はほぼ無視できる)。一方アナログで増幅する場合はノイズが問題になる。どの程度の影響があるかはカタログに「入力換算ノイズ」などという名前で記載されている(親切なメーカーであれば)。こちらを少し詳しく見てみよう。
たとえばマイクアンプの場合、アンプなしだとこんな感じになる。
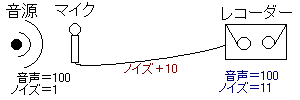
本来デシベルで表記すべきなのだが、対数が苦手な人のために単位なしの数字で表記してある。ここで「マイクにできるだけ近い場所に」アンプを入れて増幅するとこんな感じになる。

・・・はずなのだが、前述のように、アンプが発生させるノイズを足してやらないと正確な計算にならない。結局このようになったとしよう。

赤枠がアンプのノイズを加味した部分(このように「アンプの前でこれだけノイズが入ったのと同じことになる」という考え方で計算したものが「入力換算ノイズ」で、ここでは入力換算ノイズが「1」であると仮定している)。
最初のつなぎ方(直結)だと、最終的な音声100に対してノイズが11、最後のつなぎ方(アンプあり)だと最終的な音声10000に対してノイズ309である。このままではわかりにくいかもしれないが、デジタル増幅で「音声が20000になるように」加工すると、前者のノイズは2200、後者のノイズは618になる(結局「音声とノイズの比率」が問題なわけで、専門用語では「S/N」という)。ポイントは「アンプの後ろで入るノイズの影響が小さくなる」ということである。
念のため上記のS/Nをデシベルでも表記しておくと、マイクの直前の段階で40db、直結の場合で19db、アンプを入れた場合で24dbくらい(アンプを入れることで5dbくらい改善したことになる:ただしあくまで「考え方の例」であって、実際に上記のような条件で録音することはまずないと思う)。計算自体は「log(S / N) * 20 =」の「S」に音声「N」にノイズの大きさを代入してGoogle電卓を使えばすぐにできる(反対に「10^(R / 20) =」の「R」にデシベル表記のS/Nを代入すると、ノイズが音声の何分の1かわかる)。
このようにアンプを使ったノイズ対策が可能なのだが、条件が2つある。1つは「おもなノイズ源よりも手前に」アンプを入れること。たとえば上図で「マイクの手前までに入るノイズ」が50くらいあったら、アンプより後ろのノイズに対策してもあまり効果がない(マイクより前にアンプを入れることはできないのでお手上げ)。もう1つはアンプの入力換算ノイズが極端に大きくないこと。これは常識でわかると思うが、たとえば上図でアンプの入力換算ノイズが5くらいあったら、アンプを入れる意味が薄くなる。
上記のような使い方をするアンプとして「マイクアンプ」(マイク/ラインアンプまたはマイクプリアンプと呼ばれることもある)が代表的だが、エレアコギターのピエゾピックアップやコンデンサマイクに付属しているアンプも(最初からセットになっているのでただ使う分には意識しなくて済むが)似たような目的で使われる。これらは「極力手前に入れよう」という発想を突き詰めて、結局内蔵にしてしまったもの(マグネティックピックアップにもアンプ内蔵型のものがあり、アクティブピックアップと呼ばれ、ノイズ対策が重要なベースなどで好まれる:ピックアップと一体化していない場合は「ブースター」と呼ばれることも多い)。
なお、デジタル処理の機器を「普段マイクアンプを置いている場所と同じくらいマイクの近く」に置く場合、ADコンバータ(アナログ信号をデジタルに変換する部品)が24bitリニアPCMくらいの精度で「本当に正確に」動いていれば、マイクレベルの信号をライン入力に突っ込んでも目くじらを立てるような不都合は生じない(というか、マイクの出力を忠実に記録しようと思ったらその方が都合がよいかもしれない)。ただし2010年現在一般に普及している機器では、マイクレベルの音はアナログアンプに通してレベルを合わせることが多い。反対の発想でレベルを合わせる変わった例としてローランド(EDIROL)のM-10DXがあり、マニュアル(多分初版)のブロック図を見る限り、マイクレベルの信号はそのまま、ラインレベルの信号は単純に抵抗をかましてから一緒くたに処理している。
「プリアンプ」という名前が出てきたが、直訳すると「先に使うアンプ」のことである(「マイクプリアンプ」は「マイク用の先に使うアンプ」)。たとえば、マイクの音をラインレベルに増幅して、いろいろ加工をして、最終的に大きなスピーカで鳴らす場合、こんな感じになる。
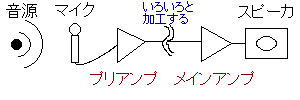
なぜ後ろのアンプが「ポストアンプ」でなく「メインアンプ」と呼ばれるのか、筆者は理由を知らないがとにかくそう呼ばれる(通信関連などではポストアンプという用語も普通に使うし、PEAVEYのギターアンプなどに「プリゲイン」「ポストゲイン」という表記はある:PAなどで大型スピーカ用のメインアンプを「パワーアンプ」と呼ぶこともある)。もしかすると、昔のフォノアンプ-メインアンプという呼び方を引き摺っているだけかも(当てずっぽう)。
呼び方はさておき、アンプを分ける理由はいくつかある。いちばんの目的は「普通のオーディオ機器」で音声を処理することである(当たり前だが、ほとんどのイフェクタやプロセッサは「デカいスピーカを鳴らせるレベル」まで増幅してしまった信号を上手く扱えない:周波数特性と最大増幅率の関係もあるが、アンプの内部仕様なのでここでは無視)。また、メインアンプの入力換算ノイズが多少大きくても問題にならなくなる(プリアンプよりも後ろで入ったノイズは影響が小さくなるため:マイクを直結できるイフェクタの場合はアンプを内蔵していることがほとんど)。
さらに、アンプで音を歪ませるときにもメリットがある。アンプ(とくに真空管を使ったもの)というのは「限界以上に増幅」させようとすると音が歪む(英語で「オーバードライブ」という:控えめに増幅していても多少は歪む)。たとえばこんな感じである。
一番上が元の波形、下はいろいろな設定でオーバードライブさせた波形(実機ではなく真空管アンプシミュレータを使った)。
これをやるには、当然アンプのボリュームを思い切り上げてやらなければならないのだが、小さい音量でオーバードライブの音を出したいこともあるだろう。そういう場合、プリアンプのボリュームをガッチリ上げて、メインアンプのボリュームは控えめにしてやるとうまくいく。さらに、プリアンプだけ別のものに取り替えれば歪み方を変えることもできる(チューブアンプは機種や球や個体差でかなり音が変わる)。そういうわけで、ギターアンプなど音を歪ませる目的で使うアンプでも、プリアンプとメインアンプが分かれていることが多い(プリの設定はGain、メインの設定はVolumeというツマミで行う機種が大半)。
マイクにはマイクアンプ、ギターにはギターアンプ、ベースにはベースアンプなど、それぞれの楽器や機材に特化したものを使うのが手っ取り早くまた使いやすい(ただし、ブルースハープをマイクで拾ってギターアンプに通すなど、あえて目的外利用することもないではない)。デジタルアナログを選ばなければ、上記はどれも数千円で十分な性能のものが手に入る(マイクアンプについてはミキサーなどに付属しているものでもOK)。キーボードアンプは例外で、とくに欲しい人(ライブで使うとか)以外いらないと思う。あとはPAをやるときにパワーアンプを使うくらいだろうか。
真空管アンプ(チューブアンプ)についても少し紹介しておこう。上でも少し触れたように、今はデジタルのシミュレータがあるので、音を歪ませるためにどうしても必要なものではない。デジタルに比べるとノイズも多く、出音が不安定で、融通も利かない(デジタルなら、多数のアンプの特性を1つのハードorソフトでシミュレートできるが、実機の場合せいぜい球を替えるくらい)。電源のオンオフで球にストレスがかかる(ので、大型アンプでは電源スイッチでチューブの運転を維持したままスタンバイスイッチでチューブ以外の回路を操作遮断するものが多い)し、適正な出力負荷がかかっていないと壊れてしまう(とくにギター用のアンプヘッドで、キャビネットに繋がず電源を入れるとそのまま昇天する)設計のものもある。
しかし、好みの問題ではあるが、チューブにはチューブの味があって捨てたものではない。なんといってもやはり、常に同じ音が出てくるよりはいろんな音が出た方が楽しい(チューブアンプというのは同じ設定やツマミ位置であってもいろんな音が出る:音が安定しないということでもある)。なお、チューブアンプを使うとギターの上達が速くなるという説があるが、筆者は「チューブが暖まるまでの間ヒマなのでチューニングを頻繁かつ念入りに行うようになる」のと「球の寿命がもったいないのでいったん電源を入れたらしばらく練習する」のと「比較的高価な消耗品を使っているので時間を惜しんで弾く」のが主要因だと信じている。
話を戻そう。ぜひ必要なものではないが、リスニングやエンジニアリングで扱うのと奏者として扱うのではかなり印象が変わる(筆者の場合リハスタで遊ぶときに触るだけだが、自分で鳴らしてみる前はチューブ嫌いだった:エンジニアリングだけやってる分には単に面倒が増えるだけだし)ので、機会がもしあれば試してみて損はないだろう。
もう本当にこの辺にしたいのだが、2012年現在、D級アンプ(デジタルアンプ)は歪みが多い増幅装置で云々という説明をいまだに見かける。そりゃあローパスをかける前の波形だけ見れば元の波形とずいぶん異なっている。しかしそれは「アンプの出力」ではない。そんなことを言い出したらプッシュプルアンプなんて途中では半波しかない。ここまで読み進めた読者は、テンテンのデータから滑らかな波形を取り出せることを承知していると思う。実はそのときに使われるのがローパスフィルタで、アップコンバートもローパスフィルタの活用法の1つに過ぎない。そして、D級増幅の途中で生じる歪み(カクカク)もまた、ローパスフィルタで除去することができる。
この処理は高い精度を簡単に得られるのが特徴で、なぜそれが可能なのかは数学と電気の知識がないと理解しようがないため省くが、結果としての入力波形と出力波形の相似度(結局歪みの少なさ)でいえば、普通に作られたD級アンプは非常に優秀である。そのうえ発熱も少なく小型化が可能で、もし欠点を挙げるとしたら、接続する負荷の許容範囲が狭い(ローパスフィルタの特性を狂わせないため)ことくらいだろう。
だいたいA級アンプを無意味に持ち上げたがるのがよくわからない。A級だから偉いと言えばそれで権威があるように思っているのかもしれないが、A級アンプなんてごく普通の技術である(昭和時代の普及品ブラウン管テレビの音声部分は、A級アンプ+背面開放キャビネットが主流だった:消費電力が小さく風通しがよいためA級アンプの欠点である発熱の多さがネックにならず、回路を単純にできる利点が狭い設置スペースにマッチする賢いやり方)。
反対に今度はD級だから偉いようなことを言い始める人が出てきたり、真っ赤な顔で「A級アンプは歪みがないから素晴らしい」と叫んでいた人たちが「D級は無味無臭で面白みがない」なんて謳い出したり、世の中本当に忙しいものである。筆者にも骨董趣味はある(自分が使う場合限定なら楽器用チューブアンプも好きだし、昔のデカいラジオの音なんかも悪くないと思う)ので、自分の好みやスタイルを追及する人にとやかく言う気はないが、趣味は振り回すものでなく嗜むものである。
エレキギターというのは回路的にかなり特殊(というか「鉄弦が震えてるんだからコイルで電気に変換しちゃおうよ」という最初の発想の時点でクレイジー)で、いろいろな迷信の出元にもなっている(実機の構造など具体的な話には直球勝負のエレキギターのページで触れている)。
たとえば「ケーブルで出音が変わる」なんてのも、実際エレキギターにいろんなシールドを挿すと音色がさまざまに変化するのだが、途中にローパスフィルタを挟むのと同じことをやっているのだから当然である(林正樹ホームページというサイトの解説が詳しい:音が「ケーブルの中で劣化している」という理解だとちょっとズレることに注意)。また、ピックアップのコイルと接続した回路の抵抗や静電容量でRLC回路ができるため、大きな容量を繋ぐと共振の仕方も変わる。
この「ハイ落ち」問題はよく話題になるが、ぶっちゃけた話、トーンツマミを回すという単純な対応でなんとかなることが多い(もちろん音のキャラは微妙に変わるが、好き嫌いの問題)。というか、ソリッドギターというのはもともと「ハイが過剰になりがちな」楽器(フルアコなどの音と比べればわかる:より正確にはハイミッドが強く出て5KHzくらいから上はそれほど多くない)で、ストラト(リアのみトーンがない)やごく古いテレorエスクワイヤーを除くたいていの機種では(トーンツマミを全開まで回しても)高音成分をいくらか(グランドラインに)捨てている。この部分の回路を故意に無効化すると高音が極端に強いジャリジャリの音も作れて、そのサウンドが好きだという人も一部にいる(トーンコントロール回路については一庵堂というサイトの解説が詳しい:スイッチの劣化や設計が古いアナログイフェクタを多数繋いだ場合のいわゆる「音痩せ」に関する解説なども興味深いし、ケーブルの話も突っ込んでいて面白い)。
さらに、ギターアンプでは500~1000Hzあたりの中音域を削っている(Duncan's Amp Pagesというサイトで公開されているTone Stack CalculatorというソフトでEQ特性をシミュレートできる:キャビネットにフルレンジを使う都合もあるのだろうが、それでも「素直」とは言い難い)ものが多く「DIを使った直接入力は低音域が弱い」というのは勘違いである(高域の減衰が少なく中域も削らないため、結果的に低域が弱く感じるだけ)。
ハイ落ちといえば、ギターアンプやヘッドフォンアンプなどで「高域の変化」が取りざたされることがある。マグネティックピックアップやダイナミック式ヘッドフォンドライバなどはコイルを主体とした回路なので高域になるほどインピーダンスが高くなるが、相手側の機材が(入出力周波数の範囲内で)フラットな特性ならば、周波数によって効率が一定しないことになる。これは単に仕様の問題であって、やはり、相手側回路の「品質」が問題なのだと考えるとちょっとズレることに注意して欲しい。
音痩せという表現もよく用いられ、とくにイフェクタのバイパス方式に関連して言及されることが多いが、いわゆるトゥルーバイパス(ハードワイヤーバイパス)は、それ単体では音痩せしやすい方式である。ちょっと考えればわかることだが、ギター>スイッチ>ドライブアンプと繋ぐより、ギター>バッファアンプ>スイッチ>ドライブアンプと繋いだ方が信号の劣化やノイズの混入ははるかに少ない(大型のループスイッチャーにバッファアンプ内蔵のものがあるのはこのため)。あえてローファイな音を作りたいのでなければ、さっさとDIなりプリアンプなりに通してから使うのが賢明である(アンプの電気的特性で大騒ぎする人は直前にリバースDIでも仕込もう)。プリアンプさえ通してしまえば、スイッチを1つや2つ通過しても信号の質はあまり変わらなくなる(考慮すべきケースとしては、3PDTスイッチを使った機械式トゥルーバイパスで漏話(クロストーク)をもらうパターンくらい)。
ブリッジアース(弦アース)に関して、人体がアンテナの役割をしてノイズを拾うのでそれをグランドラインに逃がしてやるという説明はどこから出てきたのだろうか(2012年11月追記:確認は取っていないが『エレクトリックギター完全版』(1998.8.1版、監修=竹田豊)の129ページがモトだそうだ)。簡単に実験できるが、弦に手で触れないとノイズが乗る状態でギターをスタンド(念のためフルプラスチックのものを選ぼう)に立て、人が遠く離れてもノイズは消えない。それから、これもよく言われる話だが、たかだかラインレベルの出力をするのに20Vも30Vもバイアスをかける必要はない。1V@開放端=0dbV≒2.44dbuであることを考えればすぐにわかる。
これも変なデマの元になっているのでちょっと触れておきたい。注意点は結構多いが当たり前の話ばかりなので、ほんのちょっとだけ気をつければトラブルを回避できる。
なお、マイク録音のノイズは大部分が「マイクアンプより前で入ったもの」と「アンプ自体が乗せたもの」である。マイクアンプは100倍とか1000倍などといったオーダーで増幅を行うので、マイクアンプより前に入ったノイズも盛大に増幅される。電気で動く機器(パソコン、エアコン、テレビ、アンプ、スピーカ、蛍光灯など含む)、強い電流が流れるケーブル(電源タップ、床下や壁の中の電線、スピーカケーブルを含む)、電波を出す機器(携帯電話や無線LAN含む)などからできるだけ離れたところで、マイクとマイクアンプを短いマイク用ケーブルで接続しよう。当然、音声ノイズ源からもできるだけ離れる。
また、ムービングコイル式のダイナミックマイクがホワイトノイズやヒスノイズのおもな発生源になることはほぼ考えられない(3000度くらいまで熱したらわからないが、先に壊れると思う)。ほとんどの場合、ヒスノイズを出すのはアンプである(ので、アンプ内蔵マイクの場合は注意が必要:「ノイズの小ささを優先しない設計の」極限ローエンドマイクに見られる例だが、マイクに内蔵されたアンプのノイズが大きすぎると、他ではフォローのしようがなくなる)。感度が高いマイクを使うと音声ノイズを拾いやすくなるという面倒な説もあるが、ノイズに対する感度が上がると同時にシグナル(録音対象)に対する感度も当然上がっており、ノイジーになる理由がない(音声ノイズの影響が大きくなるのはオフマイクにしたときである)。応答が極端に非線形で、エキスパンダがかかったような音が録れるマイクを使ったなら話は別だが、普通に使っていてそういう現象が起こる心配はあまりない。
これはAudacityで作った200Hzのサイン波にフェードアウトをかけて、FastTrackUltraからMSP5に出し、CM5で拾ってFastTrackUltraに戻したもの(上が再生波形、下が録音波形:Audacityでノーマライズと頭出しをしてある)だが、突入応答の乱れこそあるものの、ダイナミクス自体はだいたい線形である。
ついでに、コンデンサマイクの優位性は「オフマイクに適する」ことと「高域まで特性を均しやすい(あるいは高域に意図的なクセを作りやすい)」ことで、ドラムス用オフマイクなどには絶好であるいっぽう、ヴォーカルのオンマイク録音などに使ってもコンデンサマイクならではの特徴は微妙にしか現れないし、よほどドギツい味付けがされているのでもなければ「ごく普通の音がそっくりそのまま録れる」だけである。これに「平凡な音しか録れない」と言いがかりをつける人がおり、コンデンサマイクの特性を活かした製品を当たり前に作っているメーカーには本当に気の毒なことである(クセのあるマイクが好きだという嗜好はもちろん悪いものではないが、真面目なメーカーが普通に作ったモノに「コンデンサマイクなのにこんな音か」はちょっと酷い)。
ドラムスとパーカッション以外のポミュラー楽器(ヴォーカル含む)の場合、筆者としては「ダイナミックマイク>マイクアンプつきのアナログミキサー>パソコンのライン入力」という構成がいちばんスッキリするように思うのだが、ライン入力がないパソコンだとサウンドカードの増設が必要になる。
重要な情報:
この項の説明は他の項の説明と比較してもかなり怪しく、ムリヤリな計算も多用している。話半分に。
周辺機器の話でたまに悪者扱いされるバスパワーについて。バスパワーというのは、USBとかFireWireなど(バスと総称される)の電源機能(英語でパワー)のことである。ライン出力を行ううえで、バスパワーは決して非力ではない。
まずバスパワーの出力から。USBだと5Vで、ローパワーデバイスは100mA、USB2.0のハイパワーデバイスは500mA、USB3.0だと900mAが上限。FireWireの6ピンは8V~33Vで最大1.5A。USBハイパワーの5V/500mAを例に挙げると、電力として2500mW(=2.5W)に相当する。
いっぽう、1KΩのラインアウトから10KΩのラインインに20dbV(開放端で10V)の電圧をかけると、回路全体には0.909mAの電流が流れ、だいたい9.09mWくらいの電力になる。ライン出力が2本(ステレオの右と左)の場合、アンプへの投入電力を出力の10倍と見積もって、変圧などのロスを50%としても、400mWの供給で足りる。
電力が不足するのはヘッドフォンアンプの部分である。モニタ用ヘッドフォンの許容入力(これ以上の入力があると壊れる、というカタログ値)は、AKGなどのもので200mWくらい、ソニーなどのもので1000mWくらいなので、壊れないギリギリのレベルまで使う場合、上記と同じ計算だと4000~20000mW(=4~20W)くらい突っ込まなければならない。実際、たとえばAT-HA2(テクニカ製のヘッドフォンアンプ:ステレオ2系統出力)の仕様を見ると「電源:DC15V(ACアダプター)」「消費電流:300mA(最大)」「最大出力レベル:300mW/ch」となっている。
ただし、たとえばソニーのMDR-CD900STは「音圧感度:106dB/mW」で「最大入力:1,000mW」だから最大入力時の音圧は136dbで、普通の人なら機材より先に耳が壊れる。AKGのK240MK2とK271MK2は「感度(1kHz) 91dB SPL/mW」で「最大許容入力 200mW」だから最大入力時の音圧は104db(歪みがまったく生じなかった場合)で、このくらいの音なら出すことはありそう。欲しい最大音量と感度も問題になることを忘れると妙なことになる(感度が10db高ければ同じ音圧を10分の1の電力で、感度が20db高ければ同じ音圧を100分の1の電力で出せる)。
マイクアンプはそれほど大飯食らいではなく、上で計算したライン出力とそれほど変わらないオーダーになる(出力がラインレベルなのだから、まあそうだろう)。たとえばAT-MA2(やはりテクニカ製のマイクアンプ:2系統入力だが同時1系統のみ有効)の仕様を見ると「電源:DC9V(ACアダプター)」「消費電流:30mA(最大)」「最大出力レベル:+2dBV(1kHz、T.H.D1%時)」となっている。ファンタムも大したものではなく、たとえばAT8541(やはりテクニカ製のファンタム電源:48Vで1チャンネル)の仕様を見ると「電源(内部) 単3形アルカリ乾電池×4」「電源(外部) 9~15V.DC300mA.ACアダプター(センター負極)対応」「消費電力 310mW(6V,負荷電流4mA時)」となっている。アンプやファンタム以外の部分は、非常に小さな電力しか必要としない(液晶のバックライトなどは例外だが、たいてい設定でオンオフできる)。
まとめて計算してみよう。もし(規格上は2500mWだが、実用上)2000mWの電力が安定して供給されていれば、マイクアンプ2つとライン出力2本とその他プロセッサなどをまかなっても十分足りる(上記の計算だと、せいぜい1000mWくらいになる)。しかし、さらにヘッドフォンアンプを追加しようとすると、最大出力5~15mW/chくらい(ポータブルCDなどのヘッドフォン出力と同程度)のものになり、モニタ用ヘッドフォンを限界音量で鳴らすにはちょっと足りない(仮に電力で100倍なら、20db足りない計算)。ここで出力をムリヤリ引っ張ろうとすると、ノイズやら歪みやらの問題がいろいろと出てきて面倒なことになる(さらに大電力が必要なスピーカアンプでは、ヤマハのパワーストレージなど、電気を貯めて対策している機種がある)。
ようするに、一般的な外付けサウンドカードなどを動かす上でバスパワーが非力なのは間違いないのだが、割を食うのは(良識あるメーカーの製品であれば)ヘッドフォンアンプの部分だけである。昔(少なくとも90年代くらい)から「電池駆動の機器はヘッドフォンの音量をあまり上げずに使え」というバッドノウハウがあったが、それを守っていればあまり問題ないことが多いはず。大きな音が欲しい場合は、効率の高い(小さな電力で大きな音が出る)ヘッドフォンを使う手がある(これも電池駆動機器と同様)。また、電力供給自体が安定しないと話が始まらないので、USBの場合はとくに、ハイパワー機器の同時接続数に注意したい(データの渋滞にももちろん注意)。
また、電源自体が不安定であるという問題もなくはないのだが、機器単体でなら対策(新しい経験の日々の記録というブログに自前の電気工作による実例が掲載されている:書いているのはCD2WAV32の作者さん)はそれほど面倒でないため、普通のメーカーが作っている音楽用の機器が実用上の悪影響を受けることは(不良品でもなければ)あまりないだろう。
そういったことよりも、バスパワーがらみで問題が起きるとしたら、複数機器の併用時ではないだろうか。未確認情報を継ぎ接ぎした話で、この項の話の中でもことさらに怪しいのだが、
どうしてもイレギュラーな使い方をしたい場合、USBを給電にしか使っていない機器はパソコンに繋がっていないセルフパワーのUSBハブから電力を取るなど、電気的なネットワークが重複しないように工夫するとよい。
他のページですでに触れた話ばかりなので、リンクメインにしておく。もし変な個所が表示される場合、一度ブラウザの「戻る」ボタンで戻ってから再度リンクをクリックすれば大丈夫なはず。
ぶっちゃけた話、曲を作る上で「覚えなくてはいけないこと」はそう多くない。打ち込みだけでやるならだいたいこんな感じ。

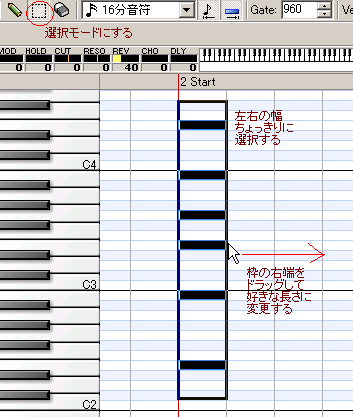
注意が必要なのは音が「ドレミ」ではなく「CDE」で表示されることくらい。スライス機能は選択モードに切り替えてから
切りたいところをクリックしてCtrl+Lキーでできる。パターンスライスは
イベントメニューにある。コード入力支援は
ツールメニュー。選択モードで音符を「左右の幅がちょうどになるように」すべて選択、選択範囲の右端をドラッグすれば長さを調整できる。
長さや強さは最初から数字で指定しておくこともできる。
ドラムスはこんな感じ。
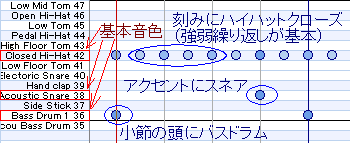
設定もとりあえず2種類わかればなんとかなる。
あとはバスドラムかスネアを(必要なら)ちょっと増やしてメロディっぽいものを適当に入れてやればこんな感じになる(もうちょっと詳しい話は一足飛びの目次から未経験者向けの記事を見繕うなり外部リンクから他のサイトを当たるなりして欲しい)。ここまでできれば自分が磨きたい部分を磨いていけばいいだけなので、窮屈に考える必要はどこにもない。
作曲も編曲も(もっといえば録音やミックスも)「競技」ではなく、この技を入れたから何点とかいった話にはならない(もちろん、あえて競技的にやるのもそれなりに面白いだろうが、そういうチャレンジは十分上達してからやればよい)。初心者だけでなくベテラン(と思われる人)の作品にさえ、取ってつけたような「技」を盛り込んだことで台無しになっているものが多くあり、非常にもったいない。
初心者でありがちなのは、トライアドのスリーコードで間に合うところに奇妙なコードを捻じ込んだり、ベースやドラムスを意味なくフラフラさせるといったパターンだろう(わかっていてあえてやる分には問題ないが、初心者がムリに真似たり、慣れた人でも無自覚にやった場合はたいてい破綻する)。当たり前の話だが、基本パターンからの脱却を目指す前に、基本パターンでそれなりのモノを作れるようになるのが先決である。
ただし、普段から他の人が作った音楽を注意深く聴いて、自分の曲に使えそうな音や面白い曲ができそうな音を拾っては「どうやって出しているのか」を探り、実際に音を出してその効果を確認し、また演奏技術を磨く、というのは必要な努力なので誤解なきよう。
これももう何度も同じこと書いてるしねぇ。何よりもまずモニタをなんとかしよう、というのは何度繰り返したか覚えていない。やたらと高いものを買えばそれでいいというのではなく、使う前にサインスイープくらいは確認しようと、そういう話である。必要最低限のことをやらないで機材がどーした音源があーしたソフトがこーしたと騒いでもまったくナンセンスである。
ただし、出音の「調整がしやすい」機材があると便利なのは間違いなく、ごく繊細な微調整を求められる場合や、いろいろな特性でのモニタを一元管理したい場合などは、相応のハードなりソフトなりが必要になる。反対にヘッドフォンで素の出音のみモニタするなら、ぜひ必要なのは「ヘタっていないエンジニアリング用ヘッドフォン1つと、マイク録音するなら録音用のヘッドフォン1つ」だけで、他の影響はさして大きくない(ただし、これも繰り返し書いているが、自分の頭に合うものを選ぼう)。
上の話を疑う人は、同じCDを別の機材(たとえばステレオコンポとポータブルCDなど)で再生して同じヘッドフォンで音を比べてみよう。大音量域だとヘッドフォンアンプの性能差で多少の違いが出ることはあるが、念を入れるならラインで出して同じアンプ(業務用のヘッドフォンアンプかアクティブスピーカが理想だが、ステレオコンポやラジカセのライン入力でも音の比較はできる)に入れてやればよい。
このとき、機器のEQやバスブーストなどはすべてオフに、音量は同程度に設定しておくこと。またパソコンで実験する場合は「CDをリッピングしたうえでサウンドカードのネイティブサンプルレートに変換したwavファイルを再生」しよう(ちょっと面倒な事情があるが説明は割愛)。スピーカでモニタしたい場合はまず「スピーカを鳴らし切れる部屋」を用意しなければならない(詳しくは機材関連のスピーカのページに書いたが、一般住宅だとけっこう大変)ので、ほとんどの人にとっては貸しスタジオを使った方が早くて安いと思う。機器の性能やら特性やらを云々する前にまずマトモなスピーカスタンドに乗せて壁から離して正三角形に近いレイアウトを作り機器が想定している音量を突っ込めということは繰り返しておきたい。
その他は・・・やたらと「プロユース」の機材にこだわっても効率悪いよとか「オーディオインターフェイス」という呼び方が紛らわしいからやめない?とか宅録のネックは(部屋の改造に手をつけない限り)マイクアンプだけだからそこに数千円使っとけばド素人がパソコンのオンボードサウンド使ってもこのくらいの音は録れる(詳細は録音と加工のページを参照)とか、しょーもない話が多いのがなんとも。
ほとんど蛇足だがもうひとつ、ソフトウェアもハードウェアも、上手く動かない/十分な性能を発揮できない一番の原因は「使い方が間違っている」ことである。機材や音源やソフトにケチをつける前に「動作条件を満たしているか」「使用目的は適切か」「取扱説明書通りに設定したか」を確認しよう(筆者もアホをやらかすことがあるが・・・そうならないようにみんなで努力しよう)。それから、説明書を完全読破はしないまでも、せめて「FAQ」や「よくある質問」は読んでおこう。
理由の二番は「使用環境が酷すぎる」ことである。たとえばパソコンソフトの場合シロウトが常用しているマシンの中身なんてまさにグチャグチャで、イカレた常駐ソフトやマルウェアの1匹や2匹飼っていてもまったく不思議ではない。またたとえば、それなりに気合を入れて自宅スタジオを作ったとしても、プロが設計したスタジオでプロがセッティングする前提のハードウェアがちゃんと動く保障はどこにもない。ある程度やむを得ないといえばやむを得ない話だが、やはり、説明書に「こういう使い方はやめてね」と書いてあることだけはしっかり避けておこう。
機材やソフトに変な妄想を抱いている人(やそういった妄想を煽りたがる人)が多いように見受けるが、道具に対して従属的な態度でいるうちは何を使っても「自分が出したい音」なんて出せるわけがない。使う側が「主」にならければ話が始まらず、結局は自分の手と耳を使って経験を積むしかない。反対に言えば、道具がどうこうなんてのは、経験を積んでから自分の出したい音に即して考えればいい話である(ただし「学習に適した道具」というのももちろんあるので、頼りになる(物知りな、ではなく)経験者と仲良くしておくのは大きなメリットになる)。
一番手は、プラグがキャノン(XLR)だと音がよくてフォン(TRS:サイズによって標準プラグとかミニプラグなどと呼ぶ)だと悪いというもの(画像はどちらもWikipediaJPへの外部リンク)。そりゃ接点面積の問題なんかは微妙~~~に影響するだろうけど、金具の形が変わっただけで音が激変するわけがなかろうに(ちゃんと調べてはいないが、どうやら、キャノンに繋ぐと普通のアンプ、フォンに繋ぐと補助用の簡易アンプに接続される仕様の機材で、使い方を間違えたうっかりさんが騒ぎ始めたのが元らしい)。なお、S/PDIFに光ケーブルを使うとメタルケーブルよりもエラーが増えるというのは間違いではないが、正確には「メタル>変換>光>変換>メタルで送るとメタルだけで通すよりもエラーが増えることがあり、またオプティカルコネクタの作りが甘く半差しや汚れた状態が頻発した時代がある」である(もちろん現在は、不良品でなく推奨される使い方を守れば普通にビットパーフェクトな伝送ができる精度になっている)。
ついでだからこれも言っとこう、真空管もてはやすのはいいけど、チューブは「時間や温度などとともに特性が変わる=出音が一定しない」のが味(だからこそデジタルでのシミュレートが難しい)なんだから常に「今出てる音」を確認しよう。「終わった」球を使い続けながら「やっぱりチューブでないと云々」などと言っても空しいだけだろう(終わってから味が出る球や、出力が安定するまでの短い時間にだけいい鳴りをする球もあるあたり、チューブってのはまた不思議なものではある)。出音を安定させたいならトランジスタアンプとチューブシミュレーターを組み合わせるのがよい。
それから「エージング」なんて作業が必要(あるいは有効)な機材は、真空管(最近はエージンク済みで出荷されるものがほとんど)を使った回路と、マイク/スピーカ/ヘッドフォン(とくに国外メーカー製品の一部、極限ローエンド、自作品など:普通の製品でも許容入力-10dbで数時間くらいの馴らし(いわゆるバーンイン、初期不良の洗い出しにもなる)はした方がよい)、あとは人間の手や耳や脳(どんなにすばらしい特性の機材でも、聴く人の耳が鳴り方に慣れていないと取り出せる情報量が減る:この「馴らし」は不可欠)くらいである。あれだけ使い方にうるさいヤマハさんですら、モニタスピーカのマニュアルに「エージングしろ」なんて書いてはいない(壁から最低1.5m離して設置するのが理想、とは書いてある)。
疑う人は、この次ヘッドフォンかスピーカ(ただし極限ローエンドでない国内有名メーカーもの)を買ったとき「左右片方づつ」エージングしてみよう。片方だけエージングが終わった段階で左右の音を聴き比べても、両方新品の状態で聴き比べたときからバラツキの有意な増加はないはずである(ただしこれはフェアな方法ではなく、もしバラツキが増加していても人間の耳のエージングが追いつかないため判別できないと思われる:とことんやるなら測定用マイクで録音して比べてみればよいが、十分なデータ数を揃えて統計的な検証をしないと無意味なので注意)。
なお、人間の耳以外に数百時間のオーダーでエージングが必要な機材(楽器含まず)はほとんどない。許容入力-10dbくらいのピンクノイズを流せるならまず10時間もかからない。目安の数字で言えば、1年に200日平均5時間づつ使うと合計1000時間になり、極限ローエンドの製品だとこのくらいのオーダーで「寿命」がくるし、モニタ用(売り文句ではなく実際に業務用として多用される)の製品だとほとんど特性が変化しないはずである(そのくらいのオーダーで特性がコロコロ変わったら業務用のモニタにはとても使えない)。
音源については・・・良し悪しよりは相性と好みの問題なので、各自で好きなものを使えばよろしかろうと思うわけだが、どーも窮屈に考えている人が多いように見受けられる。また2010年4月現在、生楽器の音を録音したサンプリング音源を使ったからといってそれだけで生楽器っぽい音が出せるほど便利な世の中にはなっていない。有料のものについては楽器と一緒で、運命を感じたなら衝動買いもアリだろうが、普通に買う人は(可能な限り)試奏くらいした方がよい(他人が鳴らしているのを聴いただけでは自分に合うかどうか判断できないことが多いので)。アコースティック楽器とは形態が違うが、シンセ選びなどは楽器選びとそっくりである。
妙な話も多く「MIDIといえば外部音源かサウンドボードの付属音源で鳴らす」のが普通だった時代に「これを使えば音源がないサウンドボードでもMIDIを鳴らせる」と人気になったシロモノをいまだに「代表的な音源」として紹介している例なんかはちょっとアレ。もっと酷い話では、バランスが悪く製作者が引っ込めた音源をやたらと誉めそやし、根負けした(?)製作者が配布を再開した途端誰も話題にしなくなった、なんてのもある。素で言っているのならともかく、イタズラだとしたらちょっと度が過ぎるんじゃないかなぁ。
編集ソフトについてはさらに混沌を極める。ディザの性能がどーしたこーしたという話はどこから沸いたのだろうか。ディザというのはランダムノイズ(色つきディザもあるが、一般住宅で16bitディザの色を聴き分けるのは逆立ちしても不可能)なのだが・・・産総研のSpin diceでも積んでるのだろうか(積んで意味があるとも思わないが)。ちなみに32bitから24bitに(1回だけ)変換するような場合は、ディザがあってもなくても実用上の差はない(-144dbFS程度のノイズがランダム分布だろうと偏った周波数分布だろうと問題にならないから)。また、もし24bitから16bitへの変換にディザが必要なのだとしたら、低い録音レベルで24bit記録したデータをデジタルで48db増幅する際にも、ディザが必要だということになる(8bit分の情報が潰れるのは同じなので)。
デジタルミックスでソフトが違うと音が変わるという主張もあるが・・・そりゃ「音が変わる方のソフト」が壊れてるだけだろう(たとえばアンプのIM歪みを先読みして逆相の歪み成分を先に仕込んでおくとか、単純な足し算以上の処理ができないわけではないが、そこまでやったら完全に余計なお世話である)。やはり、未経験者に初心者お断りのスパルタソフトを勧めたり、知識のない人に「最新版」と称してベータバージョンを勧めたりする物好きな暇人がたまにいる。さらに酷いのは「安いから」とか「製作者が個人だから」とかいった理由でソフトの性能にケチをつける珍説。ここまでくるとコメントのしようがない(ハードウェアならまだ「値段が高い素材を使った方が性能がよくなる気がする」と言い出す人の心情が想像できなくもないのだが)。
リスニング寄りの分野には「笑うしかない」話がもっと豊富にある。あまりヒステリックに叩くのもどうかと思うが、まぁ「そういうこともあるんだな」程度に知っておくのは損ではあるまい。多数のリンクを掲載しているサイトに、Hinemosuというブログのオーディオオカルトコーナーや楽譜の風景というサイトのオーディオの真実というページがある。
一応断っておくが、筆者は(「アホを煽ってムシれるだけムシろう」という態度が露骨なメーカーは嫌いだが)高価な機材や音源やソフト自体が嫌いなわけでは決してない(むしろブランドモノには弱い)し、投資が必要な部分があることを否定する気もない。ただ、予算は有限なのだから頭を使ってコストパフォーマンスを上げなければ効率が悪いし、どうせ使うなら本来の能力を発揮できる使い方をしてあげたい。何度も繰り返している話だが、明確な目的意識もなく半端な買い物をするのが一番ムダである。自分が出したいのはどんな音で、今出ている音とのギャップはどこにあって、それを埋めるためになにをどう使えばいいのか把握しなければ、なにを手に入れても持ち腐れるのが目に見えている。
ここまでに紹介した中には「普通にやってりゃそんなのわかる」というものもいくつかある。たとえばリニアフェイズEQの特性などは、わざわざ波形やスペアナを確認するまでもなく、ちょっと耳で聴けば「なにかおかしい」ことに気付くのは難しくない。ただ、そこで原因を追求せずに切り捨ててしまうのはあまりおトクでないように思えるのである。
実際「音がFFT臭くなる」と言ってFFT系の加工全般を毛嫌いする人や、IRフィルタ全般を「音がボケる」といって敬遠する人はけっこういる。リニアフェイズEQがFFTでIRフィルタを回しているのは事実だが、動作原理を理解して実際の挙動をテストしてみれば、FFTやIRフィルタ自体が無条件で「ダメ」なわけでないことは普通に理解できるはずである。使い方が適するかどうかの問題はあれど、FFTもIRフィルタも実に有用な技術なので、使えないものと決め付けてしまうのはもったいない。
リニアフェイズEQのことを悪く言った感じになってしまったが、実際問題、ポータブルオーディオ向けのマスタリングで1dbでも音圧を稼がなくてはならない場合などはマキシマイザーが大活躍する(重宝するのを通り越して必須)わけで、性能自体が粗悪なわけでは決してない。結局みんな「道具」なのだから、必要なときに必要なものを使えばいいだけなのである(反対に言えば「今なにが必要でなにをどう使うと適するのか」をどれだけ的確に知っているかという部分が腕の見せ所になる)。
たとえば手元にハサミとカッターがあったとして、どちらが刃物として優れているか思い悩むのはナンセンスで、それぞれがどんな作業に適していてどう使うと効率がよいのか、ということを気にした方がずっと生産的である(中華包丁のように、1本で「なんでもできる」ことに「美学」がある道具もないではないが、その道の専門家ならともかく、アマチュアがやたらとこだわることもないだろう:ちなみに、中華包丁にも用途別のラインナップがないわけではなく、斧や鉞と見紛うような愉快な形状のものもある)。
残念なことだが「必ず~とは限らない」という言い方が、学問的な良識のある人を黙らせる(あるいは「一般向けでない言説」を強いる)ために、また学問的な知識のない人を欺くために格好の材料になる。
たとえば電卓で「1+1」を途方もない回数繰り返し計算すると、いつか必ず「2」以外の計算結果が出る(もちろん故障や不良品や操作ミスによるエラーは除外)。この主原因は外来ノイズ(ここでは天然の放射線など防ぎようがないものに限定して考えている)なのだが、もし外来ノイズが一切ない理想的な環境を得られたとしても、不可避な内部ノイズ(量子の振る舞いなど、物理的にどうにもならないもの)によってエラー率は絶対にゼロにならない。しかし、ノイズによって電卓が計算を間違う確率は故障や操作ミスでおかしな計算結果が出る確率よりもはるかに低く、実用的にはまず問題にならない(マトモな設計の電卓なら)。
上記の説明を読んでわかるように、正確に物事を記述しようと思うと注釈や専門用語や条件設定などがやたらと増える。またメンドクサイことに「電卓は必ずしも正しい計算結果を示さない」という主張そのものは(実用的でないが)正しい。おまけに素人目には「電卓が変な答えを出した理由」がわかりにくい(他に頼るものがないと、多くの人は「経験」や「体験」に依存しがちである)。ぶっちゃけ、権威がありそうなチャンピオンデータやキラーソースと、相手の自意識に連動させた初歩的な話術があれば、勉強の足りない相手を騙すのはわけもないことである。
たとえば2010年3月現在のGoogle電卓は「(10^250) * (0.1^400) =」という式に対して「0」という答えを返し、「(10^250) / (0.1^400) =」や「(10^400) * (0.1^400) =」という式は計算できない(「0.1^150 =」や「10^150 =」なら正しく計算できる)。これは(ノイズでも故障や操作ミスでもなく)電卓の設計上の選択(ようするに仕様)に過ぎない(上記は少し変わった例だが、普通の電卓でも「(1 / 3) * 3」を「正確に」計算できるものはあまりないと思うし、内部が2進数処理になっているものだと10進数の「0.05」などを「正確に」扱えない場合もある:どちらも実用上はほぼ問題ない)。
しかしもし仮に「Google電卓は不正確です、ためしに(10^250) * (0.1^400)を計算させてごらんなさい、電卓というのはそもそも必ず正確なものではなく量子がああして宇宙線がこうして(以下略)」とやられると(再現性が極めて高い時点で量子や宇宙線と関係ないのは明白だが)100人中99人までは騙されなくても、1人くらいは騙せる人がいるかもしれない(困ったことに、そうやって騙される人に限って声がデカかったりする:自分の知り合いで一番騙しやすそうな人のことを想像してみよう)。
そしてその誤解を解こうと思うと、またクドクドした説明が必要になり、たいていの場合マトモに聞いてもらえない(同じ専門用語を使うにしても、煙に巻くための説明なら、正しい知識を提供するための説明よりも圧倒的に少ない知識と話術で事足りる:クドクドしているから正しい説明だということにはならないことに注意・・・するまでもないか)。
上記の誤導には騙されなかった人でも、先に触れたギターシールドの話ならどうだろう。予備知識がない状態で、エレキギターとアンプとケーブル数本を前に、直流抵抗値など無意味なパラメータを大げさな測定機材でチェックしたうえ、音を出しながら「違いがわかりますか」「耳がよいですね」「あなたのような一部の人にしかわかりませんが、実は、このようにケーブルの違いが音質に与える影響は(略)」とやったら、騙せそうな知り合いが1人くらいはいないだろうか。
いったん上の説明を受け入れてしまうとあとはなし崩しで、やはり音を出しながら「ギターほど顕著ではありませんがラインの音も(略)」と畳み込まれて、うっかり「確かに違うね」と答えたところで勝負あり、後からエレキギターの回路について知る機会があったとしても、そこからプレーンに導けるはずの理屈を拒絶せざるを得ない状況に追い込まれる(誘導する側が「嘘は言っていない」ことに注意)。
似たような話で「試験条件がムチャ」という場合もある。たとえば「この電卓はあの電卓よりよい計算結果を返しますが、使う前に山伏として2年ほど修行を積み、鰯の頭を柊と大豆の枝に刺して門戸に飾り、2時間ほど滝に打たれて身を清める必要があります」という主張があったとする。常識で考えればムチャクチャだが、科学的な思考ができる人というのは、そういう一見ムチャな主張であっても「追試せずに否定する」ことに抵抗を感じるものである(学者として地位がある人ならなおさら)。
かといって上記の条件で追試できるかというと、個人の負担としてはいかにも大きすぎる。結果として黙ってしまう人が多い(せいぜい「電卓の計算結果と操作する人の修行に関連はないはずだ」くらいの物言いになる:気合の入った人なら電卓の動作原理から説明を始めるかもしれないが、そうなると「一般の人」はまずついていけない)。さらに悪いことに前提条件の基準を明示していないため、たとえ気合と根性で追試して「有意差なし」という結果を得たとしても「修行の仕方が悪い」の一言でさも論破したかのように装える。
結局個人個人が「ちょっとの手間」を我慢して智恵と知識を仕入れるしかないのかなぁ、という気がする。情報を発信する側としては、多少の曲解を許してもプレーンな情報をという意識だろうか(どちらも、筆者自身しっかり実践できているとはとても言えないのがなんとも)。
シグネチャモデルの楽器というのはいい音が出る。
楽器の特性や仕様が云々という話ではなく、普及品に名前やロゴを印刷しただけのものであっても差し支えない。なぜなら、楽器に自分の好きなミュージシャンの名前が入っていると気分がよいからである。演奏者のメンタリティが変われば、当然出音も変わる。音声加工をする場合も、気分よく操作できる機材を使うのと、イチイチ引っ掛かりのある機材を使うのとで同じ結果は出ない(根気の続き方が変わってくるのも大きい)。
主体的に音を出したり加工したりせず単に音を聴く立場でさえ、音声的には同じでも、気分が変わればまったく違った音に聴こえる。疑う人はレトルトカレーを2つ(イマドキの技術水準なら、味付け自体はほぼ変わらないはず)買ってきて、1つは普通に、もう1つはクソの写真かなにか鑑賞しながら味わってみるとよい。クソの写真はちょっとあんまりにしても、空腹時と満腹時で同じ味を感じるかどうか確かめてみるとよい。味覚ほど顕著かどうかは別にして、同じことが聴覚にも起こる。
他のページでも繰り返していることだが、メンタルな要素の影響力は意外なほど大きいため、ぜひ十分なケアをして欲しい。筆者に言わせれば、ソフトやハードの細かい仕様なんぞよりよほど重要な事柄である。
これは誤解云々というより筆者の解釈紹介のようなもの。他の項に増して内容が怪しい。
まずはクラシックから。英語だとclassical musicで、Collins English Dictionaryによれば「any style of music based on long-established principles of composition and polyphony and marked by stability of form, intellectualism, and restraint」だが、第一義的には「a style of music composed, esp at Vienna, during the late 18th and early 19th centuries. This period is marked by the establishment, esp by Haydn and Mozart, of sonata form」のことである(English Dictionaryオンライン版より)。
どういうことかというと、18世紀後半から19世紀前半のクラシカルな作風と19世紀のロマンティックな作風(この古典派~ロマン派の揺れは、西洋文化史上ほぼ常に存在するもので、対立軸というよりは流行や風潮に近い)が共存する状況において、前者をclassical、後者をromanticと呼んだのが始まりである(前者の代表はハイドンとモーツァルト、後者の代表はシューベルトとショパン、間にいるのがベートーベンという格好)。もっとも狭義のclassical musicは、1800年ごろヨーロッパのメインストリームだったスタイルを指すことになる。なお、コテコテのクラシックを「バリエーションを追求しない音楽」だと思っている人がなぜかいるようだが、モーツァルト時代にさえこのくらいのこと(外部リンク)はやっていたわけで、何か別のものと取り違えているのではないかと思われる(聖歌の一部などには、安定感が宗教的に重視されてずっと同じ響きの効果音のようになっているものもある)。
で、厄介なのは、シューベルトやショパンによる「ロマン派音楽」も今日のセンスでは「music based on long-established principles of composition and polyphony and marked by stability of form, intellectualism, and restraint」(つまりクラシック音楽)に違いないということである。なぜそのような変化が出てきたのかといえばJazzが登場したからだろう。
Jazzの発祥自体はBuddy Boldenが活躍した19世紀末より少し前くらいだろうと思われ、その時点ではブルース(録音が残っていない時代の本当に古い形のブルース:担い手としてはもちろんアフリカ系の移民、形式的にはアイルランドの影響が大きいらしい)との区別が明瞭でなかっただろうと想像できる。それがダンス音楽になり商業的な性質も帯びてディキシーランドジャズになる。楽器も、金管とギター(コントラバスだけは擦弦)くらいだったのが、ドラムスや木管やピアノが加わり、バンドが大規模化するに従って指揮者も登場する。
これらの変化の背景に、マーチングバンド出身者やワルツ奏者、クラシックの教育を受けた人たちの(おそらくは経済的な理由を主とする)参加があったことは想像に難くない。形式的にも、独奏協奏曲や変奏曲のコンセプトが組み込まれる。ようするに、ブルースがまずあって、そこに西洋音楽の楽器や方法論や人材が流入してきたということになる。結果的に、スイングジャズや初期のビバップはロマン派音楽にかなり接近する(もしロマン派音楽をクラシック音楽に入れるなら、スイングジャズほどクラシックに近い音楽はない:もし入れないのなら、ロマン派音楽が一番近い)。
さてではポピュラー音楽とは何を指すのか。ふたたびCollins English Dictionaryでpopular musicを引くと「music having wide appeal, esp characterized by lightly romantic or sentimental melodies」とある。ちょっと定義が広い。これだとロマン派音楽おろか、狭義のクラシック音楽も一部はポピュラー音楽に分類され得る。クロスリファレンスになっているpop2には「music of general appeal, esp among young people, that originated as a distinctive genre in the 1950s. It is generally characterized by a strong rhythmic element and the use of electrical amplification」とある(いづれもEnglish Dictionaryオンライン版より)。
想像に過ぎないが、「日銭に結びつく音楽」のことをpopularと称し、それが蔑称化したのがpopなのかもしれない(英語圏では語の短縮で侮蔑を表現することがある:たとえばJapanese>Japなど)。また歴史的経緯として、初期のJazzやブルースが日銭商売と強く結びついていた(芸術家の表現活動でも素人の趣味娯楽でもなく、プロの演奏家による興行だった)ことは注目に値する。ともかく、50年代くらいにクラシック音楽はすでにポヒュラーでなく、Jazzはモダンジャズの草創期、他方でエレキ音楽(ブロードキャスターの発売が50年)が興隆してゆく。
ひるがえってブルースは、これまた微妙な立場にある。もともとは民俗音楽であって「wide appeal」や「general appeal」を狙って作られたものではなく、自然発生したものだろう。しかし、エレクトリックブルースなどは比較的ポピュラーであったし名前の通りエレクトリック楽器も使っている。21世紀初頭の状況で言えばエスニック系のフュージョンや商業化した南米音楽が似たような状況といえるだろう。これらの境界はもともと連続的なものである。
チャックベリーやエルヴィスプレスリーが登場してロックンロールになると、ポピュラー音楽と呼ぶ以外になくなる。同時代のイギリスではスキッフル(弦楽器をテキトーに弾きながらテキトーな歌をテキトーに歌うという、おそらく最初期の歌謡パンク:ロニードネガンを初めとするプロもいてマーケットも(期間的には一瞬であるものの)大きかったが、ジャグバンドと呼ばれるテキトーな面子がテキトーな楽器(あるいはその代用)を持ち寄ってテキトーな場所で演奏する形態も流行した)のブームが鎮火するかしないかくらいのタイミングで、ロックンロールはその後釜に座った形になった。この辺がイギリスのわからないところで、バンドブームのお祭り騒ぎが終わった後にホンモノさんがザクザクと出てくる。
時系列で並べると、アメリカでのロカビリーブームが1955年ごろ、エルヴィスプレスリーのRCA移籍が1956年、バディホリーのコーラル移籍が1957年、スキッフルブームが一気に下火になったのが1958年、モータウンレコードの設立が1959年、ベンチャーズのデビューが1960年、ビートルズとローリングストーンズとボブディランのデビューが1962年、クラプトンのヤードバーズ移籍が1963年、ジミヘンドリクスが軍隊から追い出されてミュージシャンになったのが1964年(除隊は63年)、といった感じ。これらの人々が好き勝手な場所で好き勝手なことを一斉に好き勝手にやったため、ロックンロールとは異なる「ロック」という意味のわからないものができあがった。
物事をややこしくするのはイギリス人のお家芸で、ピンクフロイドやキングクリムゾンなどのプログレッシブロック、ツェッペリンやディープパープルなどのハードロック、ドアーズなどのサイケデリックロック、それらを全部ごちゃ混ぜにするだけしておいて自爆したクリームなどが入り乱れる。アメリカ人はアメリカ人で空気が読めず、ローカル色を出したい人やイギリスっぽくやりたい人やブルースやR&Bやロックンロールに憬れる人やロックをソフトにやりたい人などが自己主張をする。60年代後半にデビューしたのは、サンタナ、ジャニスジョプリン、スージークアトロ、カーペンターズなど(エアロスミスは70年)。
一方のブルースはというと、パーティーソング(もっといえば宴会芸)だったはずがなぜか愚痴の歌になったり、日本に輸入されてマイナーキーの歌謡曲の呼称になったり、細かい脱線や枝分かれはあるもののアメリカでは一定のジャンルを確立し、エリッククラプトンやラリーカールトンやマイケルランドウなど他のポピュラー音楽と掛け持ちでブルースもやるギタリストもいる。Jazzも一定のジャンルとして発展し、他のジャンルとの融合を試みる人たちがフュージョンをやり始めた(が「ポピュラー」の代表の座は他に明け渡した格好)。クラシックも依然ジャンルとしては大きく、前衛主義になったり懐古主義になったりと紆余曲折はあるものの、現代なりのクラシカルな音を追求する試みがなされている。
日本への本格的な流入が早かったのはおそらく、明治期から積極的に取り入れられたクラシック音楽に次いで、戦後に「アメリカの音楽」として入ってきたJazzだろう。ハワイアン音楽の流入もあったようで、移民の多さやアメリカ本土と日本の中間に位置する地理的条件も影響したと考えられる。これらを土台に、Jazz風のバンドをバックに(多くの場合クラシックの経験を持つ)歌手が歌ういわゆる歌謡曲がジャンルを形成する(西洋音楽の楽器と日本語の歌という形式は、初期のJazzといくらか似ている)。ブルースという語が輸入されたのもおそらくこの頃で、Jazzのフィルターを通して入ってきたブルースがさらに日本的に変化したため、オリジナルとは似つかないものになったのだろう。歌謡曲の演奏形態である流しが(少なくとも形式として)先祖帰りを起こしているのは興味深い現象である。
エレクトリック音楽は、プレスリーを中心とした(日本で言う)ロカビリーとベンチャーズ(1962年と1965年に来日)を中心としたサーフミュージックに分かれて流入したと推測できる。とくにハワイアンミュージックへの親しみという受け入れ土壌があったサーフミュージックは歓迎された。平行してアメリカンフォークも入ってきたようで、ピート・シーガーが1963年に来日している。田端義夫が54年にギターを紛失して気になっていたソリッドギターを手に入れたというエピソードがあるので、楽器自体はもう少し前から入ってきていたのだろう。1966年にビートルズが来日するとなぜかグループサウンズブームが始まる。フォークソングもなぜかフォークになり、グループサウンズブームの鎮火を待つようにしてニューミュージックブームが起きる。こうやって並べると、商業音楽の可能性を(当時の業界人が見えていた範囲で)実験し尽くしたザ・ピーナッツが、59年にデビューしてるのは特異に見える。
これらが急速に移り変わる中、人材の重複(とくにエレキギターやドラムスやホーンセクションなどはJazzやサーフミュージックや歌謡曲の経験者以外に熟練した奏者がいなかったと推測できる)や活動場所の隣接(いわゆるジャズ喫茶の多様化)などによりそれぞれが混ざり合い、日本独特のポピュラーミュージックが形成されたのだと思われる。
たとえば、発売当初の1951年当時、Telecasterは189ドル50セント、Esquireは149ドル50セント、1957年当時でテレが199ドル50セントだったらしい。1942年発売当時のJ-45が45ドルだったのも有名な話で、34年に14フレットネックジョイントにモデルチェンジしたD-28が100ドル、1952年当時のLes Paul Customが325ドルで、レギュラーモデルは225ドルだったそうな。
一方アメリカには連邦最低賃金というのがあり、39年の規定で時給0.30ドル、45年の規定で0.40ドル、50年の規定で0.75ドル、56年の規定で1.00ドルである(これは貧富の差が激しい当時のアメリカ社会で最低所得層を守るためのもので、1990年時点で3.80ドルだったことを考えると、日本の感覚でいう「最低賃金」よりは相当安い:その後20年で大幅に増額され、2009年には7.25ドルになった)。
42年当時の0.3ドルを2013年現在の500円に換算しても、51~52年当時の0.75ドルを現在の500円に換算しても、57年当時の1ドルを500円に換算しても、ギター1本の値段は10~15万円くらいである(大量生産されるようになるともっと安くなる)。
これを、為替相場の変動や日本の物価などとムリヤリ結びつけて何倍にも見せかけようとする人たちがいる(戦後日本のインフレ率はアメリカの比ではない:日本の製品だって、1990年ごろのものを中国にでも持っていけば「当時の年収で何年分」なんて話は簡単にデッチ上げられる)。突飛な数字が出てきたときにはちょっと用心した方がよい、という話。
オーディオオカルトなんかに関連する話で「定性的には間違いではないが定量的な評価が欠けている」などという指摘を目にしたことがある人は多いと思う。この「定性的」「定量的」という用語が、話をわかりにくくしていることがあるようだ。おおまかな理解としては、定性的評価というのは「~という性質がある/ない」の評価、定量的評価というのは「~という性質がどのくらい強いか」という評価である。
もっとはっちゃけよう。ようするにたとえば「ラインケーブルを替えると音が変わる」という主張は定性的には間違いでない。言い換えると「変わるか変わらないか」という部分にだけ注目すれば正しい。しかし「どの程度変わるのか」を無視して「変わる」という部分だけ叫ぶのはばかげている。意味ありげなグラフを持ち出して「科学的な分析の結果確かに変わるっ!」と主張している人のデータをよく見ると「10km使うと100KHzより上が0.1dbくらい変わる」ことを示したデータだったりする。
もっと極端な例を挙げてみよう。地球はほぼ球形で自転しているため、地表から離れたところと地表に近いところでは前者の方が時間の進み方が遅い。この主張自体は間違っておらず正しい。しかし「腕時計の時刻を正確に保つには高さを一定にしなければならない」という主張はナンセンスで、なぜかといえば「どの程度時間の進み方が変わるのか」ということを無視している、つまり定性的な評価だけで定量的な評価が欠けているからである。
もちろん、量を考慮していればそれでよいわけではなく、たとえば「一般乗用自動車は戦車よりも丈夫である、なぜならば後者の方が10年後に壊れている割合が多い」なんて主張もナンセンスなら、「米を食べた人は例外なく200年以内に死んだというデータがあり、米には致死性がある」なんていう主張もナンセンスである。
以下余談:普通に考えればわかるはずのことでなぜコロっと騙される人がいるのか、いろいろと見解はあるだろうが「自分は科学的な説明を理解できる」と過信している人が多いのも一因ではないか。たとえば数学の教科書、あれには文句なしに科学的なことが書いてあり、しかも書き手の側には「正しい知識をできるだけ容易に得て欲しい」という意図と努力が大いにあるわけだが、誤解なく理解した人の割合はどれだけだろう。悪意を持って誤解を誘う説明を「たしかにナンセンスである」と判断するのは、その何十倍も難しい。それを「簡単だろう」と(過去の経験も省みずに)考えてしまうメンタリティこそが「騙しやすさ」の源になっているのだと思う。
たとえば20Hz半波の正相波と20Hz半波の逆相波(ここでいう正逆は、16bit符号ありPCMで正の値を正相、負の値を逆相としたもの)を体積が小さい密閉型ヘッドフォンで大音量再生(追試する人は、耳や機器にダメージを与えないよう小さめの音量から試すこと)すると、多くの人はブラインドでも判別がつくだろうと思う。
たしかに違う応答がなされてそれを知覚できるし、ヘッドフォンのドライバが正電圧と負電圧でまったく同じ動きをすることもないだろうし、音声が負圧から始まるのは不自然だと言われればそんな気もしてくる。しかしだからといって、即座に「正信号で正圧を生じるのが正しい設定だ」というのは飛躍が過ぎる。
普通のオーディオ機器では位相なんてあちこちでひっくり返っているし、圧倒的大多数であるマルチマイク録音ではあえて逆相にしたマイクが混じっていないことを保証する手段がなく(というかエンジニアリングの手法として位相反転は普通に使われる)、実際の音楽再生ではドップラー歪み(スピーカのページのオマケで触れた)も絡んでくるため、事態はいっそう複雑になる。
たったひとつの変化だけに目を奪われて、それをコントロールするためにどのようなトレードオフがあり、実用の場でコントロールのためのコストや制限やデメリットに対してどれだけのメリットがあり、自分はどのような条件でどのバランスを好むのかという問題を無視するのは、軽率に過ぎる。それらの材料が出揃って初めて議論や考察に着手できるのであって、結論や見解ははるか先にある。
事の是非や議論の行く末は別として、この長い(はずの)道のりが見過ごされることがままある、ということを肝に銘じたい。
ある程度の経験がある人に聞きたい。
イフェクタの調整をやったときに、ああこれは微妙だな、しかしちょっと良くなった、この辺がジャストじゃないのか、と5分なり10分なりすったもんだして、実はそのイフェクタはバイパスされていましたというオチがついたことはないだろうか。
筆者はあるし、もし「ない」という自称ベテランがいたら、その人の言うことは眉に唾を付けて聞く。
何が言いたいのかというと、自分の(というのがちょっと酷な表現だとしたら人間の)耳がどれほどいい加減なものか、あなたは知っていますよねということである。
筆者に言わせると、耳のよい人、同じ音声からでも異なる音楽を読み取れる人ほど見事に騙されるはずで、恥ずべきことではないように思う。むしろ、耳なんて当てにならないが最後に頼るものは耳しかないということを承知している人、自分のやっていることの危うさを理解してそれをコントロールする努力をしている人こそ、本当のベテランと呼ぶに値すると思う。
ではその本当のベテランに改めて聞きたい。あなたが得た知見をほんの少しだけ世の中に広めることができたら、音に関わるあれこれが僅かでも噛み合った状態に近付くのではないだろうか。また敢えてそうする動機を、あなたは持っていないだろうか。
お節介は承知の上で、そういう問いをすることにも意義はあろうと思い、蛇足を伸ばしてみた次第。
{kind=link}
{kind=link}