上記と同じ条件で位相反転なしだとノッチフィルタをかけたような谷が現れる。
このことから、クロスオーバー部分周辺の周波数特性が位相に依存して大きく変わることがわかると思う。
サンプリング時のS/Nについて、物理的な上限を考えてみる。あくまで「どんなに大風呂敷を広げてもこれ以上は必要ない」という数字を追求するので、実用的な需要とは必ずしも一致しないことに注意して欲しい。たとえば「中の人間がブラックアウト/レッドアウトを起こすから、耐G服の着用を前提としても、乗用自動車の加速力/制動力は10G程度を超える必要がない」とか、そういった話と似たレベルの議論である。
前提知識として、全体のホワイトノイズレベルを0dbとして、約-18.27dbのホワイトノイズ源1つを完全に除去すると、全体のホワイトノイズレベルが1db下がる。また約-7.69dbのホワイトノイズ源1つを完全に除去すると全体のホワイトノイズレベルが3db下がることを覚えておいて欲しい。
つまり、もっとも大きなノイズより18db程度小さいノイズであればよほど数が多くない限りほとんど問題にならないし、8db程度の差でも大きな影響は出にくいということである。これはホワイトノイズやピンクノイズだけでなく、周波数と位相がそろった正弦波またはそれを重ね合わせたものでも同様である。
電気信号を時系列でサンプリングした場合、ショットノイズというノイズが生じる。エイリアシングノイズ(折り返しノイズとも:想定よりも高い周波数の信号が混じっていた場合に生じる)や、サンプリング自体が不正確であれば(正確な周期でなければ)それによるノイズももちろん記録され得る(また、広義には「サンプリングの際のノイズ」に含め得る)が、ここではそのような「実装の不備」については考慮しない。
ショットノイズは量子の振る舞いが統計的なばらつきを持つことから生まれるノイズで、理想的なショットノイズはホワイトノイズ分布となり、S/Nは単位時間あたりの量子数の平方根に等しい。
-55dbV at 1Pa(開放端電圧に換算すると28.73mV)で内部抵抗600Ωのマイクを600Ω系の回路に組み込んで1Paの音圧に晒した場合、検出回路側にかかる電圧は都合14.36mVになり、23.94μAの電流が流れることになる。
1A=1C/sであり、ジョセフソン定数とフォン・クリッツィング定数の協定値から1A=1C/s≒6.24 * 10^18 e/sとすると、23.94μA≒1.49 * 10^14 e/sである。これを48KHzでサンプリングする場合、3.10 * 10^9 e/sampleとなるから、ショットノイズのS/Nは√3100000000≒55600≒95dbとなる。
ショットノイズ自体は、信号の1/2乗(=平方根)に比例して強くなる(信号が100分の1になるとノイズは10分の1になり、結果的にS/Nが10分の1になる)。たとえば上記の例でショットノイズのS/Nが95dbということは、1Pa(≒94db SPL)の音声に対して55600分の1のノイズが入っているということで、音声に換算すると-1db SPL相当のノイズとなる。マイクに入力する音声を0.001Pa≒34db SPLにすると、音声が1000分の1になるので電流も1000分の1=-60dbになり、S/Nは√1000分の1倍つまり30dbの悪化して65dbに、音声に換算したノイズは-31db SPL相当になる。
一方、マイクの感度が-35dbV at 1Paに上がると電圧が10倍になり、結果的に回路を流れる電子数も10倍になるため、S/Nが√10倍になる(すなわち10db改善して、1Paの音声入力に対して105dbになる)。ラインレベル(-10dbV)の信号だと同様の計算で117.5dbくらい、+10dbVの入力があれば127.5db程度になるだろう。また、サンプルレートを192KHz(4倍)にすると1サンプルあたりの電子数が4分の1になるため、S/Nが√4分の1倍=半分になる(すなわち6db悪化する)。
電圧をN倍にしてもショットノイズのS/Nは√N分の1にしかならず、一方で電力はNの2乗倍になるため、現実的に考えると、高電圧をかけてショットノイズを抑えるのもあまり現実的ではない(電圧を100倍にしてもショットノイズは10分の1にしかならず、電力は1万倍になる)。サンプルレートでの対応も、たとえばサンプルレート48KHzを24KHzに落としても3dbくらいしか改善が見込めないため、あまり効果的とはいえない。これらの数字から、ラインレベルの電気信号をサンプリングしてAD変換する場合、120db前後がS/Nの物理的上限になるだろう。
実用面を考えるとショットノイズの影響はそれほど大きくなく、もっとも極端なケースとして-115dbVの信号をサンプルレート192KHzでサンプリングした場合を考えても、S/Nは60dbくらいになる(記録される信号との比であって、db FSではない)。これに対し、ライン入力のインピーダンスを10~25KΩ程度とすると、20Hz~96KHzの周波数域には常温だと-115dbVくらいのヒートノイズが生じる(計算式は後述)ため、
ここではリニアPCMの量子化ノイズ(理想的なA/D変換を行っても、記録形式の仕様上不可避なノイズ)について考え、リニアでないPCMやPDMについては考慮しない。量子化ノイズも、特殊な条件下以外ではホワイトノイズ分布をとる。やはり、クリッピングノイズ(想定よりも大きな信号が混じっていた場合に生じる)や、量子化自体が不正確であればそれによるノイズももちろん記録され得る(また、広義には「量子化の際のノイズ」に含め得る)が、ここではそのような「実装の不備」については考慮しない。
量子化ノイズは有限ビット数で表現できる値と元の波形の音圧の差によって生まれるため、元のアナログ波形の振幅にもっとも近い値を量子化後の値とする限り、ピーク音圧が1bit幅のホワイトノイズとなる(詳しくは日本シスコシステムズによる解説を参照)
他の文献をあたってみたところ、量子化ビット数をNとするとダイナミックレンジ=6.02N+1.76dbというのが正確な計算らしいが、1.76db(1.761とする資料もあった)がどこから出てきたのか筆者は理解できなかったし、些細な差なので以下では無視する(気になる人は「1.76db」で検索すればいくつか文献が出てくる:英文で検索した方がたくさんヒットする:入力が正弦波の場合に出てくる項らしい)。だいたいの値で、理想的なA/D変換の結果を記録した8bitリニアPCMだと-48db、16bitだと-96db、24bitだと-144db、32bitだと-192dbくらいのホワイトノイズが連続していると考えてよい。
ただし、音圧レベルが±0.5ビット幅以内で連続変動している個所を限定的に見ると量子化ノイズは元の波形の位相を反転させたものになり、±0.5ビットより微妙に大きな幅で連続変動しているとジジジジッというパルスのような雑音になる(8bitくらいのPCMなら容易に知覚可能だが、16bitくらいでマトモな音量設定ならまず知覚できない)。
上記2つを合計すると、たとえば-55dbVの信号を48KHz/16bitリニアPCMに変換する場合には-90db FS、-105dbVの信号を48KHz/16bitリニアPCMに変換する場合には-65db FS、-10dbVの信号を48KHz/24bitリニアPCMに変換する場合には-117db FS、-10dbVの信号を192KHz/24bitリニアPCMに変換する場合には-111db FS程度のホワイトノイズが、物理的にどうしても避けられないということになる。上記はすべてアナログ信号の振る舞いと記録形式に由来するもので、たとえば-55dbVの信号を48KHz/16bitリニアPCMに変換するとダイナミックレンジが90dbになるという意味ではなく、理想的な(あるいは無視できる程度の誤差しか生じない高精度の)処理を行っても90db以上のダイナミックレンジが得られないことを示している。
定格入力に対するS/Nを考えると、ショットノイズの大きさに比べて24bitリニアPCMの-144db FSというノイズレベルは十分小さい。ダイナミックレンジを考えると、ショットノイズが電圧の1/2乗に比例する(たとえば信号が100倍になるとノイズは10倍になり、結果的にS/Nが10倍になる)のに対し、量子化ノイズは常に一定であるため、極小音量時には量子化ノイズの方が効いてくる(ややこしい話だが、前述のとおり入力レベルが十分高い場合にもショットノイズを無視できる:結局、入力が十分大きければショットノイズも量子化ノイズも問題にならず、ノイズフロアを考える場合は量子化ノイズを中心に考えればよいということ)。
ここでたとえば最大音量を120db SPL(そこまで大きく取る必要はほとんどないが)とした場合、24bitリニアPCMのS/Nは-144dbだから、ノイズを音声に換算すると-24db SPLとなり、まったく無視できる値になる(16bitでも25db SPLくらいなので常識的には無視できる)。また、たとえば最大入力を+15dbVとしてダイナミックレンジ120dbを確保するには、-105dbV(≒0.00000562341325V@開放端≒5.6μV@開放端)の最小入力に対応しなければならないわけだが、これを信号として処理するのは素人考えにも相当難しそうである(2009年3月現在、本気系のADコンバータでカタログ上のダイナミックレンジが110dbというのは見たことがある:ヤマハのAD8HRとFostexのAC2496)。つまり、記録形式としての24bitリニアPCMには相当の余裕があり、16bitリニアPCMでも通常の範囲で不足が出ることは考えにくい。
実際の機器では上記以外のノイズ(たとえばヒートノイズやフリッカーノイズや外来ノイズなど)も何かしら入るはずなので、S/Nはさらに悪くなる。ちなみに、ヒートノイズの電圧をVn、ボルツマン定数をk(J/K)、絶対温度をT(K)、抵抗値をR(Ω)、帯域幅をΔf(Hz)とすると、Vn = (4*k*T*R*Δf)^(1/2)であり、ボルツマン定数を1.38066*10^-23(J/K)とすると、室温(300K≒27℃)において600Ωの抵抗が帯域幅20Hz~20000Hzにおいて生じるヒートノイズは、Vn≒(4 * (1.38066 * 10^-23 ) * 300 * 600 * (20000-20))^(1/2)≒4.45663803*10^-7≒0.45μV≒-127dbV、同じ条件で抵抗値が60KΩ(100倍)になると10倍増えて4.5μV≒-107dbV、6MΩ(10000倍)になると100倍の45μV≒-87dbVになる。75K(≒-198℃:液体窒素の沸点より少し低いくらい)まで冷却すれば、室温の場合と比較して6db程度ヒートノイズを減らすことができる。
録音や再生の音質は室内環境が支配的に決定する。アマチュアによる録音や一般家庭でのリスニングではこれが最大の問題なのではないかと思うが、やや情報に乏しい。わかる範囲で書いてみる。
この項目ではもっぱら等価騒音レベルを問題にして、定格入力時のS/N(ノイズが信号で埋もれるためあまり問題にならないし、微小音のS/Nより悪化することもほぼ考えられない)などは扱わない。
考え得るもっとも極端な数字では、ディープパープルが屋内で記録した117db(1973年のギネスブックに掲載:1976年にザ・フーが屋外で120dbを出して記録を更新、その後どんどんエスカレートしてマノウォーが139dbを記録するに至るが、あまりに危険な試みなので2008年にギネス・ワールド・レコーズが記録掲載をやめてしまった)と、オーフィルド研究所の実験室の環境ノイズ-9.4db程度(2008年のギネスブックに掲載)というのが挙げられる。これを最大/最小音量に設定すると、人間にとって(知覚できるかどうかを別にして)曝露自体が可能な音声のダイナミックレンジは、差し引きで約130dbということになる(が、いくら何でも非現実的な前提なので、ここではこの数字を採用しない)。
各種音圧レベルについてはさまざまな説があって一定しないが、屋外の環境雑音としては、鈴鹿市の行政案内サイトに出ている、ガード下で100db、交通量の多い雑踏・商店街で70db、静かな住宅地の昼で45db、静かな住宅地の深夜で30dbという数字を採用する。
室内の環境雑音は札幌市の行政案内サイトに出ている日本建築学会の数字を採用し、好ましい性能水準の一般住宅で35db(深夜の値らしい)、好ましい性能水準の録音スタジオで20dbという値を上限性能とする(実験用の無響室などには環境雑音を15dbくらいまで抑えたものもあるようだ)。普通の住宅地の場合「環境基本法(平成5年法律第91号)第16条第1項の規定に基づく騒音に係る環境基準」の数字では、昼間は55db、夜間で45dbとなっているので、これを下限性能としよう。
上記を勘案して、普通の練習スタジオやそれなりに手を入れた一般住宅で40dbくらい、環境のよい練習スタジオや機材持ち込み方式の録音スタジオで30dbくらい、ちゃんとした録音スタジオで20dbくらいの室内雑音があると想定する(あくまで部屋自体のノイズレベルであって、設備や機材や人間が出すノイズは無視した値)。
人間の声は、一般に70~80db@1mくらいが大声、叫び声やオペラ歌手の独唱で100db@1mくらいまで出るようである。これを10cmの距離で録音すると、マイクには大声で90~100db、叫び声で120dbの音圧がかかる(ヴォーカル用マイクの最大許容入力も110~140dbくらいである)。音源から3m離れた壁に当たる音圧は、大声で60~70db、叫び声で90dbくらい(点音源かつ開放空間かつ環境雑音なしと仮定した場合の単純計算)。
メルクマニュアルの記述によると100db(チェーンソー操作時の騒音くらい)の音量で連続2時間、115db(車のクラクションくらい)の音量だと連続15分で耳を痛める危険があるらしい。同じページに「大音量のロックコンサート」が115dbとあるが、騒音性難聴になる危険と隣り合わせなので、大音量のロックコンサートに行くときは耳栓を使おう。コンサートホールでオーケストラを聴く場合の最大音量は100db程度、テナーサックス@1mの最大音量は88~103db程度らしい。
部屋の防音については、床置き式の個人用防音ブースで30~40db(業務用の特注品で50~60dbくらい)、6畳間100万円程度の簡易な防音工事で20dbくらいの防音性能(いづれも500Hzでの値)らしい。数万円クラスのカナル型イヤフォンには15~20db程度の雑音低減を謳っているものがあり、アクティブ型のノイズキャンセルヘッドフォンだと、3000~6000円クラスのイヤーマフタイプで12~15db、2~3万円クラスのイヤーマフタイプや1万円弱のカナルタイプで15~20dbくらいである(いづれも「最大でこの程度の効果を発揮し得る」という値だと思う)。防音専用のものだと、イヤーマフやフランジ耳栓で25db、スポンジ耳栓で30~35db程度の性能らしい。
繰り返しになるが、以下では音声ノイズだけを考慮に入れ電磁ノイズ(コントラバスやベースギターなどの低音楽器が入ると、ハムノイズの問題が途端にやっかいになる)を一切無視しているし、録音/再生時にはダイナミックレンジを完全に使い切るという前提に立っている(実際は、録音レベルに多少の余裕を取るし、コンプレッサーでダイナミックレンジを圧縮してしまうことの方が圧倒的に多いし、演奏の最小音量次第で多少のノイズは問題にならないこともある)。このためかなり理想的な数値が出てくることになり、実際には問題にならないようなノイズも問題になるかのような記述になるが、机上の計算であることを承知して読んで欲しい。あくまで「最大限に風呂敷を広げた」計算である。
10~20万円クラスのマイクを使った録音だとマイクのダイナミックレンジは100db前後が多いので、最大許容入力を120dbと見積もると環境雑音は20db以下が求められる(この時点でほとんどムリ)。3m離れた壁に当たる音圧は90db程度だから、壁で少なくとも40db(できれば50db)くらいは減衰させたい。140dbまで入力可能なマイクなら環境雑音40dbでも同じダイナミックレンジを確保できるが、壁の減衰も20db程度上乗せしなければならない。
簡易な防音工事(-20db)を行った一般住宅での録音をシミュレートしてみる。人間や機材も考慮した室内のノイズレベルが40dbだったとして、壁に当てられる最大音圧を70dbに設定すると、マイク設置点でのダイナミックレンジが60dbになる(かなり理想的な値だが)。このダイナミックレンジをいっぱいまで使い切ったとして、部屋以外の要因によるノイズが-78db(最大音量基準)であればほとんど無視でき、-68dbでも大きな問題にはならないだろう。スタジオなどを使うなら壁に当てられる最大音圧を考慮しなくて済むので、許容入力の大きなマイクと組み合わせればもう少しダイナミックレンジを稼げるかもしれない。
プロユースのスタジオ(50db防音)での録音もシミュレートしてみる。人間や機材も考慮した室内のノイズレベルが30dbだったとして、壁に当てられる最大音圧を90dbに設定するとマイク設置点でのダイナミックレンジが80dbになる(多少の音抜けを許容できる立地であれば、もう少し広く取れるだろう)。このダイナミックレンジを使い切るには、部屋以外の要因によるノイズは-88~98db程度に抑える必要がある。
簡易な防音工事(-20db)を行った一般住宅でのリスニングをシミュレートしてみる。人間や機材も考慮した室内のノイズレベルが40dbだったと想定しよう。6畳間(2.37m×3.64m)の両隅に壁から30cm離してリスナーの頭と正三角形をなすようにスピーカを置くと、耳からスピーカまでの距離が1.77mで、スピーカから壁(だいたい対角線の隅にぶつかる)までの直線距離は4.14mくらいになる(頭の大きさやスピーカの大きさはゼロと仮定)。リスナーから壁までの間で音圧は約7db減衰する(先にも述べたがあくまで単純計算)。壁に当てられる最大音圧を60dbに設定するとリスニングポイントでの最大音圧は67dbになる(一般に大音量でのリスニングが70dbくらいと言われるので、まあ妥当な数字だろう)。このときのダイナミックレンジはわずか27dbである。たとえばスピーカから0.6mまで接近すれば、距離が1.77mのときと比べて10db近く音圧が上がるため、ダイナミックレンジも37db近くまで取れる。
ヘッドフォンを使う場合も想定してみよう。室内のノイズレベルが50dbでノイズキャンセルヘッドフォンもしくはカナル型イヤフォンで10db遮断したとする。最大音量を115dbに設定(耳の健康を考えるとあまりよくないと思うが)すると75db、100dbに設定すると60dbくらいのダイナミックレンジになる。防音工事をせずに広いダイナミックレンジで鑑賞しようと思ったら、ヘッドフォン/イヤフォン以外の選択は考えにくい。静かな部屋でオープンエアー型のヘッドフォンを使う場合も似たような数字になる。ノイズレベル40dbの静かな部屋で、かつノイズキャンセルヘッドフォンを使い、かつ115dbの大音量でリスニングしたという非常に極端な例でも、ダイナミックレンジは85dbくらいである。
S/Nの上限の項の冒頭で前述したが、既存のノイズよりも18db程度以上小さなノイズはほとんど問題にならず、既存のノイズよりも8db小さい程度でもあまり問題にはならない。このことから一般家庭で再生する音源のノイズフロアは、どんなに理想的な見積りでも-93dbであれば十分だということがわかる。
以上を踏まえて、実際問題としてどの程度の音質を目指すべきなのか考えてみる。ノイズフロアの問題はシグナルの大きさに支配される(ようするに、デカい音をオンマイクで録音すれば相対的ノイズは小さくなる)ことに注意して欲しい。
最大限の余裕をもった音質として、ノイズフロア-93dbという数字が考えられるが、音楽用のマイク録音だと、2009年現在の技術ではプロでもまず不可能な水準である。ちなみにCDにこの音質で記録しようと思うと、16bitの量子化ノイズだけでも-96db程度乗るため、それ以外の部分のノイズレベルを-104db程度まで抑さえ込まなければならない(マイク録音だとおそらく物理的に不可能)。24bit記録ができるなら量子化ノイズ以外のノイズは-93db近くまで許容できる。
エレクトリック楽器のライン録音(アンプやピックアップのノイズはシグナルだと言い張る)に限定して-78dbくらいを目標にするなら、スタジオ(低音楽器が入る場合はとくに、アースやシールドを完備しているところを選びたい)や機材を厳選することで、熟練した人ならアマチュアでも何とかなるかもしれない。ごく大音量の音源(生ドラムとか大型ギターアンプとか:アンプが出すノイズはシグナルだと言い張る)をレコーディングスタジオで録音する場合、プロならマイク録音でもこの水準に迫れるようだ。現実的には、ほぼあらゆる環境において完璧な録音にしか聴こえないはずで、CDへの記録もラクである(このレベルなら16bitの量子化ノイズはほとんど影響しない)。ただし、デジタルデータに「端数が出る」処理を繰り返すと下位ビットがどんどん潰れていくので、編集時には24~32bitくらいのビット深度でデータを扱うべきである。
ヘッドフォンでの再生を度外視してしまえば-60db程度でも十分である(大音量のヘッドフォン再生でも、演奏が途切れて無音になる部分くらいしか気にならない:つまりゲートでなんとでもなる)。たとえば、69dbのダイナミックレンジに対して6dbの録音レベルマージンを取り、都合-63dbのノイズフロアでマイク録音して、コンプレッサーでダイナミックレンジを合計9db圧縮して、ノイズがまったく入っていない打ち込み伴奏と1:1の音量で混ぜると、最終的に-60dbのノイズフロアになる。ライン録音なら自宅で普通の機材を使っても何とかなるが、マイク録音だと自宅でやるのはかなり厳しい(前の項で触れたように徹底的な対策をすれば不可能ではないが、スタジオでやった方がはるかに安くて手っ取り早い)。
-50dbくらいのノイズレベルでも、エキスパンダや各種フィルタで対策すればかなり聴ける音になる(ヘッドフォンで大音量再生されると厳しいが、スピーカ再生ならほぼ無問題)。上記と同じ計算で考えると録音時のダイナミックレンジは59dbくらい必要で、フィルタで12db削ったとすると最終的な見かけ上のノイズレベルは-62dbくらいになる。宅録のマイク録音でも熟練した人がキッチリ対策を取れば実現可能な数字だし、スタジオを使うなら初心者でも達成できるだろう。実用上、マイク/ラインアンプ以外は激安品を使っても(変な用途のものでなければ)ほとんど問題ない(宅録の場合、ケーブルの引き回しや部屋の中の音声ノイズ対策の方がずっと重要)。
録音時のノイズフロアが-40dbを上回るような場合は、機材や環境を見直す必要があると思う。一番大きなノイズ源(パソコンのファンだったり、ディスプレイや階下からのハムノイズだったり、部屋の音声ノイズだったり)を探してそこを何とかしなければならない。マイクレベルの信号は、必ずアンプ(極力「マイクに近い位置」に置いて短いケーブルで繋ごう)を通してからパソコンに入れるようにしたい。録音時のノイズフロアで-50dbくらいを確保しておけば、その後の処理でスピーカによる小中音量再生では気にならないくらいの音質にはなる(初心者が自宅でマイク録音する場合、まずこのくらいを目指すとよいだろう)。
参考までに、打ち込み演奏にホワイトノイズを乗せたサンプルファイル(ファイル名の数字がノイズレベル:RMSではなくピーク値で、シグナルが-1.1dbピークなので本当はその分を差し引かなければならない)も用意した。さまざまな音量(耳を痛めない範囲)で聴き比べてみるとよいだろう(最初のハイハットの部分と、演奏が始まった後の部分でのノイズの隠れ方にも注目)。耳を痛めない範囲の音量設定で、-78dbのホワイトノイズを(ホワイトノイズなしのものとブラインドで)聴き分けられる人はどのくらいいるだろうか。
また、上記のサンプルにはホワイトノイズをかぶせたものしか入っていないが、実際の録音ではピンクノイズに近いものやハムノイズやバズノイズなどが中心になるため、もう少し目立ちにくくなる。こちらのサンプルはAT-VD3とMT4Xのヘッドアンプとパソコンのオンボードサウンドを使って録音したもの(ノーマライズもしていない、ただ録音しただけのファイル:右チャンネルのヴォーカルがマイク、左チャンネルのギターがラインでの録音)だが、右チャンネルに記録された最大音と最小音の差は45dbくらいである。
この音源に筆者がデモ作成に使っているヴォーカル用プリセット(ノイズ処理と関係が深いものでは、コンプ、ハイパス、エキスパンダ、シェイパーなど:ファイル配布ページ用のサンプルとしてあえて全部盛りにしてあるが、エキスパンダは普段使っていない)で加工を施した後フェードイン/アウトを入れてやるとこのようになる。
CDのサンプルレートは44.1KHzと非常に半端な数値になっている。これはCD規格制定当時、アメリカのNational Television Standards Committeeが制定したカラーテレビ用規格NTSCに準拠したビデオ信号を使ってCDを作成していたことに由来する(NTSCの水平走査周波数が15.75kHzで、1チャンネルにつき3本使って47.25kHzにしたのだが、当時の技術的制限で端の方にある走査線が使いにくかったため1/15だけ削ったらしい:2のべき乗か、せめて8の倍数にしてくれればキリがよかったのに)。MDも(多分CDに合わせたのだろうが)44.1KHzである。
一方、DVD・デジタル衛星テレビなどは48KHzで、DVD-Audioでは96KHzと192KHzが選択できる。SACDはPCMでないから単純な比較はできないが、100KHzの音波を記録できるというから、品質としてはDVD-Audioの192kHzと同程度なのだろう。記録情報のサンプルレートがCDの64倍の2822.4kHzであることから、ナイキストシャノンの標本化定理により1411.2kHzまで記録可能という解説が見られるが、再生時にローパスフィルタがかかるので、メガヘルツオーダーの超音波はたとえ記録できても(普通は)再生できないし、フィルタなしで再生したとしてもノイズに埋もれるはず(というか、もともとノイズを高域に集めてフィルタでカットするための技術)。DATでは32KHz・44.1KHz・48KHz(一部機種では96KHzなども)が選択可能で、32KHzや31.25KHzは一部のデジタルMTRやデジタルコンパクトカセットでも使われている。オーディオにはあまり関係ないが、デジタル回線の電話(ISDNなど)は8KHzである。
ではパソコンのサウンドカードはどうなのかというと、ほとんどの製品が48KHzまたは96KHzで内部処理を行っている(AC'97という規格に準拠した製品では、問答無用で48KHzにリサンプリングすることになっているらしい)。つまり、CD(や一般的なWaveファイル)を再生するときはサウンドカード内部で44.1KHz>48KHzのサンプルレート変換を行っている。この変換作業が杜撰な製品があるらしく、特殊なテストデータ(ライセンスが不明だし、再生機器を破損する可能性があるファイルなので転載しないが「udial.wav」もしくは「udial.zip」で検索すれば簡単に見つかる:ちなみに筆者は迂闊な設定でテストを行って、その後数時間くらい耳が痛かった)を再生すると明らかなノイズが乗る。また、サウンドドライバにハードウェアが対応していないサンプルレートのデータを食わせると、勝手にサンプルレート変換をしてしまう場合もある(そのため処理が重くなったりレイテンシが大きくなったりする)。
そういった「質の悪いリサンプリング」を防ぐには、あらかじめサウンドカードの仕様に合ったサンプルレートに(信頼の置けるリサンプリングソフトで)変換したデータを用いればよいのだが、これはVectorあたりで探せば専用ソフトがたくさん見つかる(Lilithのファイル変換機能にもリサンプリングの設定がある)。
ただし「質の悪いリサンプリング」とは言っても、普通は(=上記のテストデータのようにムリヤリ明確なノイズが乗るデータを作成しなければ)人間の聴覚で知覚できるようなものではなく、スペアナやオシロスコープにかけてはじめて違いがわかるような性質のものであるから、過剰に神経を尖らせる必要はない(マーフィーの法則に「マイクロメーターで測って、チョークで線を引き、斧で切断する」というのがある)。あくまで「気分的にスッキリするためのおまじない」であることを弁えておくべきである(収録時間のずれのページで紹介しているように、本当に酷いリサンプリングを行っているケースもあるが)。
詳しくはその他のページに書いたが、十分時間をかければ、音質をさほど損なわずにリサンプリングすることが可能である(サンプルレートによって記録可能周波数の上限が決まるので、高音域が抜け落ちるのは防げないが)。なお、ローサンプルレートのデータをハイサンプルレートでリサンプリングすると音質がよくなるというのは迷信である(すでに記録されているデータの精度を後から上げられるわけではない:一足飛びの妙な誤解を解消したいのページを参照、ディザについてはその他のページも参照)。
具体的な機種や基礎知識についてはオーディオ機器のカタログを眺めてみるのスピーカのページを参照。
以下で位相の問題をいくつか取り上げるが、同じ音量と周波数を持つ2つの正弦波(2πで1周期)が同じ位相(ずれなし)で合流した場合音量は2倍=log[10]2 * 10≒3.01db上がり、π/3の位相差で合流するとsin(pi/2 - pi/6) + sin (pi/2 + pi/6)≒1.73205081なので音量は2.38db上がりずれない場合と比較すると-0.625db、π/2の位相差だと同様の計算で1.51db音量が上がりずれない場合と比較すると-1.5db、πの位相差だと理論上は音量ゼロになる。
マルチユニットのスピーカで各ユニット(面倒なのでここではウーファーとツイーターの2つとしよう)に信号を分ける場合、ネットワーク回路(アンプからの信号を分岐させて、ウーファーにはハイパス、ツイーターにはローパスをかけてから渡す回路)を通して信号を整理してやる(これを省くと、スピーカが過電流で壊れたり異常音が再生されて耳を痛めたりする:ハイ/ローパスフィルタを1次フィルタ(-6db/oct)にして、それぞれ6db落ちた部分をカットオフ周波数にすると特性は良くなるが、ツイーターに周波数が低い信号がかなり入ってしまう)。
でこのネットワーク回路を通すと波形がある程度変わってしまうのだが、波形が変わっていることは即音が変わっていることを意味しない(これ重要)。efuさんのWaveGene ・Audacity・拙作のNyquistプラグインを使用して、100Hzの矩形波(100hz-sq.wav)、100Hzの矩形波を2つにコピーしてカットオフ周波数3200Hz・-12db/oct・Q=0.7のハイ・ローパスフィルタをかけ位相を反転してから合成したもの(100hz-sq-net.wav)、100Hz~16000Hzのサイン波スイープ(sine_sweep_100-16k.wav)、100Hz~16000Hzのサイン波スイープに上記と同じフィルタをカットオフ周波数だけ4000Hzに変更してかけたもの(sine_sweep_100-16k-net.wav)を聴き比べてみた(サンプルファイル)ところ、筆者には違いがまったくわからなかった。
なお、メインスピーカがバスレフ式でサブウーファーを追加する場合、メインスピーカの低域の位相特性が複雑になりがちなので、ネットワーク回路に工夫が必要になる(はず)。
ただし、実際にネットワーク回路を介してウーファーとツイーターを鳴らした場合、両方のユニットから出た音が必ずしも想定どおりの位相で耳に届くとは限らない(というか、必ずいくらかの誤差が生ずる)。この誤差の影響について考えてみる。
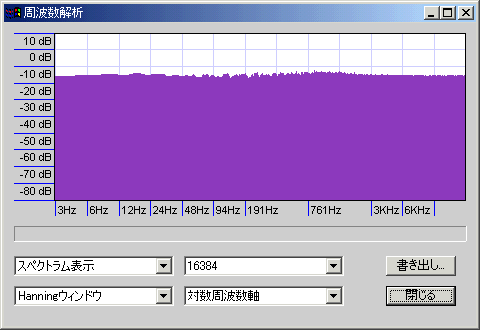
以下に、Audacityで作成したホワイトノイズ(48000KHz/32bit-float)を複製してから、前述のフィルタで削って合成した波形のスペアナの表示を掲げる。カットオフ周波数1000Hz・-12db/oct・Q=0.7・位相反転ありだとこのようになる
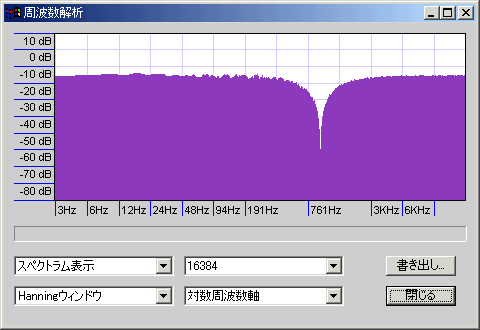
上記と同じ条件で位相反転なしだとノッチフィルタをかけたような谷が現れる。
このことから、クロスオーバー部分周辺の周波数特性が位相に依存して大きく変わることがわかると思う。
これは、次の項で触れる群遅延によってカットオフ周波数周辺の位相がずれ(=ローパス/ハイカットフィルタによって遅れ、ハイパス/ローカットフィルタによって進む)、結果として逆相加算に近い状態になるためである。上記はバタワース相当のフィルタを用いているが、もちろん、位相特性の異なるフィルタ(たとえばベッセルなど)を用いれば異なった結果が出る。
よく「マルチユニットにすると位相が乱れる」という表現を目にするが、位相が乱れても周波数帯がクロスオーバーしていなければ(ウーファーとツイーターで同じ周波数の音が鳴っていなければ)f特への影響はない。位相の乱れが影響するのは、波形が急峻に変化する部分(矩形波やアタックの瞬間など)であって、一定の音色が続く場合にはあまり影響がないといえる。位相をずらした倍音とずらさない倍音を重ねたサンプルファイルを用意したが、筆者はまったく区別がつかなかった。ただし、左右の耳に届く音の位相差(データのページ参照、定位に関わる)はまた別の話なので混同しないで欲しい。
2ユニット2chのスピーカであれば、ウーファーとツイーターが耳から等距離になるようセッティングすると、相殺/相加効果が理論値にもっとも近付くはずである(3ユニットならスコーカーとツイーターを基準にする)。ウーファーとツイータを縦に並べて、天井と床の中心と両ユニットの中心と耳の高さが一致するようなレイアウト(ついでに天井と床の材質も同じに)にすれば、反響音の特性もかなり似通った感じになると思われる(多分)。
余談になるが、-48db/octフィルタを2回重ねがけしてみたところ、ほぼ平坦な特性が得られ、位相反転時の影響もやや小さかったが、電気回路でこれを実現しようとすると損失が増えすぎるため、デジタル処理でないと面倒なことになると思う(コイルやコンデンサの数がやたらと増えて効率が下がるはず)。定位感が薄い低域のネットワーク回路(メインスピーカのウーファーとサブウーファーなど)には有効だろう(後述)。
聴覚上影響のある位相の問題として、グループディレイ(群遅延)がある。バスレフのスピーカ(詳しくは志賀@高槻さんのオーディオの科学という記事を参照)で顕著。
不都合が出る場合はオールパスフィルタ(振幅が変わらず位相だけがずれるフィルタ)を入れて補正してやるのが原則で、どの程度から知覚可能かなどの情報は上記リンク先が詳しい。
再生系だけでなく編集(フィルタ処理など)でも問題にならないではないのだが、筆者が把握している限り、マルチバンドコンプと演奏モニタ用スピーカを設計する場合以外で目くじらを立てる必要はなさそうである。
群遅延特性を「傾き1の直線」にできれば位相歪みもゼロになる(遅延時間=周期×位相なので)が、そのためにはFFTが必要になり、今度はFFTの不確定性や計算量など別の問題を考慮しなければならず、とくにステップ応答やインパルス応答の面でやっかい(結局、普通にフィルタをかけて必要ならオールパスでずらすのが順当ではないかと思う)。
前の項で「各ユニットから耳までを等距離に」と述べたが、これを常に保つことは不可能なので、補足的な対応も必要になる。周波数が高くなるほど、小さな距離の違いで位相が大きくずれるため、クロスオーバー周波数を下げると位相がずれにくくなる(以下音速=340m/sとして具体的に計算してみる)。
ツイーターのクロスオーバー周波数は1.5~3KHzくらいが多く、仮に2KHzだとすると8.5cmで位相が反転する(28.3mmでπ/3、42.5mmでπ/2のずれになる)。10KHzともなると8.5mmでπ/2のずれとなり、もはや位相を気にするだけ無駄な領域になる。ウーファーも同様で、80Hzでクロスオーバーさせてやると71cmの差で位相がπ/3ずれるのに対し、125Hzだと45cmでπ/3、68cmでπ/2のずれが出る。
サブウーファーの場合、音域を定位感を感じない範囲に留める必要がある(出力がモノラルなので)ことからも、あまり高い周波数を設定するのはよくないということになる。筆者が目を瞑って椅子の上で回りながら(他人が見ていたら非常に滑稽な光景だが)Audacityで作成した110・100・90・80Hzサイン波をスピーカ再生で聴いてみたところ、定位感がほぼなくなるのが90Hz、完全になくなるのが80Hzであった(個人差があると思うし、スピーカから高調波が出ていると基音ではなく倍音の方に定位感を感じてしまうこともあると思う)。
また、やむを得ず位相がずれてしまったときの対策として、特性が変化しても目立ちにくい周波数をクロスオーバー周波数にするという手が考えられる。1~5KHzくらいの音は特に目立つことを考えると、ツイーターのクロスオーバー周波数設定は難しい選択といえるかもしれない。
アナログのバンドパスフィルタ(またはそのデジタルシミュレータ)ではなくQMFなどのデジタルフィルタを使うと、ほとんどクロスオーバーさせない状態も作れるのだが、実際に応用してみた例などは探せなかった(素人考えに、メインスピーカ用に使うのはちょっと微妙そうだが、メインスピーカとサブウーファーの分離には都合がよさそうにも思える)。
すでに述べたが、2ユニットであればウーファーとツイーター、3ユニットならスコーカーとツイーターが耳から等距離になるようセッティングするとよい。また、高音は定位感への影響が強く位相も乱れやすいので、ツイーターとスコーカーはできるだけ近距離に置くべきである。サブウーファーは部屋のどこに置いてもよいという説明をよく見かけるが、方向はともかく、耳からの距離がメインスピーカと1mも違うようなセッティングは避けるべき。
サブウーファーの場合再生周波数が極端に低く、背後の壁からの反射音も混じって聴こえる(平面バッフル型のスピーカと同じ原理)ため、壁との距離で特性をコントロールできる。反射音が単純往復すると周波数特性が乱れる(定在波の影響を強く受ける)ので、壁に正対する置き方は避ける(PAなどでもよく使う手)。
マルチユニットスピーカを床置きする場合、ツイーターの方が上についていることが多く、ウーファーよりも床までの距離が遠い(ので反響が変わる)。これはスピーカスタンドなどを使って設置してやるか、斜め上を向けて設置することでもある程度解消できるはずである(最初から斜め置きしかできない製品もある)。
一般に、ユニット数が増えれば増えるほど良好な特性が得られる空間は狭くなるので、各ユニットから耳までの距離をしっかり調整する必要が出てくる。3ユニットにおけるスコーカーとウーファーの位相差は、設置位置の違いに対してクロスオーバー周波数がかなり低いので無視してかまわないだろう。
メインスピーカとサブウーファーのネットワーク回路について、たとえば-12db/octのフィルタで切る場合、カットオフ周波数から1オクターブ下での全体への影響は、メインスピーカがまったく役立たずだったとしても1.5db前後、0.5オクターブ下で3db前後くらいになるから、余裕を見てもプラマイ1オクターブくらいの設定でよいことになる。たとえば56.57Hzでクロスさせると、サブウーファの影響を80Hzからせいぜい110Hzくらいまで、メインスピーカの影響を40Hzからせいぜい28Hzくらいまでに設定できる。多分50~60Hzくらいがホットバンドなのだろう(メインスピーカが下で息切れする分はイコライザで補うのも手かも:そうすると環境によっては40Hzくらいで切れるケースもあるかもしれない)。
20~30Hzあたりをメインスピーカでカバーするのには相当ムリがあり、前述のオーディオの科学によると、数十万~数百万クラスで口径15~38cmのスピーカでも、40Hz周辺はあまり出ていないそうである(口径11.5cmのものも1つ含まれているが、60Hzすら出ていない:25cm以上のものはすべて50Hzをクリアしているようなのでこの辺から設計が難しくなるのかもしれないが、16.5cmでも50Hzをクリアしているものはある)。ちなみに筆者の環境(CreativeのサウンドカードSB Audigy LS+sonyのLBT-V610)では、30Hzは音波にもならない。40Hzはどうにか音波として聴こえるが、サウンドカードのボリュームを全開にすると-12dbくらいの音量で音割れする(デジタルノイズっぽいのでサウンドカードの限界かも:バスブーストなどはかけていない)。
非力なシステムの場合、定位感を犠牲にしてやや高い周波数でクロスオーバーさせるか、音の安定性を犠牲にして急峻なフィルタを使うか、低域の特性を犠牲にして低い周波数でクロスオーバーさせるか、といった選択になるのだと思う。デジタルフィルタでばっさりやる手もなくはなさそうだが、実用上どんなものなのか示した資料は見つけられなかった。
また、低音スピーカの場合、ある程度ユニットのサイズが大きくないと音が歪みやすい(=倍音が高調波ノイズとして乗りやすい)のだが、ユニットを大きくするとそれだけ質量も増えるし、小さなサイズで低音を出そうとするとバスレフ式になるのだが、バスレフというのはぶっちゃけバネなわけで、いづれにせよ応答特性(信号が入ってから鳴り始めるまで、信号がゼロになってから鳴り終るまでの素早さなど)が悪くなりがちである(高級品ではフィードバック回路を入れたり強制的に制動をかけたりしているらしい)。また、バスレフは周波数特性が明確なのでコムフィルタ様の効果が出やすいが、密閉型でも箱自体の共鳴周波数は存在する(複雑な形にして特性をぼかした箱もあるようだ)。
基本的に、スピーカの許容入力を超える出力が可能なアンプは接続すべきでない(わかっていてあえてやるならアリなのかもしれないが、誤操作による破損の可能性は常に考慮に入れるべきである)。
スピーカの能率(感度とか効率とも)は「1W入力時に正面1m先で何dbの音圧か」で示すことが多く、このページでは「~db@1W1m」という書き方を採用する。2本で5~20万円クラスのブックシェルフ/トールボーイスピーカで80~90db@1W1m(昔は90db@1W1mくらいが普通だったが、住宅事情を反映してか、最近はあまり高効率なスピーカは流行らないらしい)、PA用スピーカで90~100db@1W1mくらいが一般的である。エネルギー効率だけ見ると高効率スピーカでもせいぜい数%で、10%を超えるものはまずない(つまり、アンプからスピーカに入ったエネルギーは大部分が(音にはならず)内部で熱に変わる)。
左右スピーカの合計許容入力(実効値)はだいたい、実売数万円クラスのラジカセで5~10Wくらい、5Lクラスのコンパクトスピーカで20~40Wくらい、15~20Lクラスのもので50~100Wくらい、PA用のもので100~1000Wくらいである(常時最大入力の信号が流れるわけではないが、アンプ内蔵だとほとんどのエネルギーが熱になるため、PA用のアンプ内蔵スピーカは発熱量もものすごい)。電力がn倍になると電圧=音圧は√n倍、すなわち20*log[10](√n)db変化する(電力がmdb変化すると、音圧もmdb変化する)。
たとえば能率80db@1W1mのスピーカに100Wの信号をぶち込んでやると、信号が1Wのときと比べて音圧が20*log[10](100^1/2)=10*log[10]100=20db上がって100dbになる。これを3m離れた場所で聴くと、耳に届く音圧はだいたい80db強になる(直接音だけを考えた場合の数字で、実際には反響音が加算されるのでもう少し高い音圧になるが)。
仕事率(ワット数)が10倍になっても音圧は10dbしか上がらない(80db@1W1mのスピーカに10KW突っ込んでやっても120db@1mにしかならない)ため、ある程度以上の最大音圧を得たい場合は効率を上げた方がラクだろう(多分)。また、常用されるのは1W以下の領域であることがほとんどだろうが、むやみに上限電力を上げようとすると(家庭用の電源では駆動できないが、それこそ10KWとか)この領域が犠牲になると思われる(多分)。音圧10dbで電力10倍、音圧20dbで電力100倍、という数字は覚えておいた方がよいかもしれない。
録音スタジオリとスニングルームの問題の項でも述べたように大音量リスニングでも70db程度が普通なので、80db@1W1mのスピーカでも(距離の減衰を10dbとして)1W流せれば間に合ってしまう(100W流せば100db@1mまで増幅できるので、簡易な防音工事を行ったくらいの部屋なら十分である)。
スピーカユニットに信号を流せばそれだけで音は出るが、そのままだと、高音は正面方向に集中/低音はいろいろな方位に拡散と、音の特性がてんでそろわない。さらに、ユニットの背面からは正面とは逆相の音が出るが、低音域ではこれが正面に回り込んできて本来の低音と打ち消しあう。このため音の伝わり方を整えてやる必要がある。空気バネや閉管についての詳細は音が出る原理のページを参照。
平面バッフルは、ぶっちゃけただの板である。任意の形の板の任意の場所(特定の周波数が強調/減衰されてしまうため、普通中心を避けて取り付ける)に穴をあけ、そこにユニットをはめこむ。そのままだと背面に逃げていたはずの音をバッフルで前方に反射しつつ、背面から回り込んでくる音も跳ね返してやろうという発想である。とはいえタダの板切れ1枚なので、他の方式に比べると(同じサイズなら)低音が弱い。曲面バッフルを採用したスピーカもないではないが、筆者にはメリットが薄いように感じられる。以下で紹介するすべての方式で、バッフルの効果を併用するのが普通。
背面開放(後面開放とも:楽器用アンプのキャビネットではこの呼称の方が普通)は、平面バッフルを後ろに折り曲げて口が開いた箱状にしたもの。同じ長さの板でも折り曲げる分コンパクトになる(スピーカ前面から出た低音を反射する能力は落ちるが、背面から出た低音の回り込みを防止する能力は発揮する)。箱の出口までの空間が筒に見えなくもないが、太く短いので閉管としての振る舞いはごく弱い。エレキギターアンプなどにこのタイプが多いほか、構造が簡易なためテレビやラジオによく使われる。エンクロージャを筒として振る舞うほど長くしたものは、単純に閉管として使うパイプスピーカ(ユニット背面からの音が放出されるまでの経路で中高域を減衰させきるものは音響迷路式と呼ばれる)、筒を往復で使う共鳴管方式(ユニットから閉端までと開放端までの長さを1:2にするのが普通で、筒の長さに対して4分の1波長で共鳴することからクォーターウェーブチューブとも:両端閉管にすると8分の1波長で共鳴し、チューブスピーカなどで実装されている)、共鳴管方式の筒部分を先広がりにしたテーパードクォーターウェーブチューブ(気柱共鳴によるクセを緩和)、第一キャビネット的な構造(空気室とかチャンバーなどと呼ばれる)からスロートと呼ばれる穴を経由してホーン様経路に導くバックロードホーン(共鳴管として働くほど真っ直ぐでなく、音響迷路として働くほどデットでなく、ホーンとして働くほど広がっていない微妙な形式)などがある。
密閉は、背面開放の後ろにフタをしたような形。エンクロージャ全体がバネとして働き制動がよくなるし、ユニット背面から出た音が悪さをする可能性も低い。空気バネの特性が過剰に出る(というか高域側に出る)のを嫌ってか、重めのユニットを採用することが多く、また内部の吸音材を大量に使う傾向がある。これらが積み重なって能率は稼ぎにくい(ダイナミックレンジを下に広げようと思うと、距離を離す必要が出てくる)が、単純な設計でも素直に鳴ってくれやすい(ローの落ち方がなだらかになる)。箱が大きいとばねの作用が穏やかでユニット自体の最低共鳴周波数近くまで使え、小さいとばねの作用が鋭く共鳴周波数が高くなり、極端に大きくすると(たとえば1辺10mとか)大きな平面バッフルとほぼ同じ挙動になる。
背面バスレフ(位相反転式とも)は、背面開放の後ろに筒状の出口(ポート)がついたフタをしたような形。この筒が空気バネになってスピーカの機械的特性と合算される。また筒が十分太ければ、ユニット背面から出た音圧を回りこませて利用できる(低い周波数ほど、また高い音圧ほど空気の流速が高いくより太さが必要で、ポートの気柱の慣性インピーダンスと抵抗の比=Qbが10になるポイントで考えることが多い:ポートの共鳴周波数fbに対してポートが細いと、大音領域でバスレフが効かなくなってくる)。背面から出た音を回り込ませて有効利用するものなので効率は高めになるが、壁に密着させたり壁の中に埋め込んだりすることはできない。内部でツイーター用のエンクロージャとウーファー用のエンクロージャを分離させたものもある。
前面バスレフは、バスレフの出口をスピーカ前面に持ってきたもの。単にバスレフというとこちらを指すことが多い。背面バスレフより設置場所の影響を受けにくいが、スピーカ前面の面積が少し増える。スピーカユニットとポートの位置が近いことも、設計によっては利点になる。バスレフの出口から位相や周波数特性が乱れた中高域の音が出てくると面倒なことになるのだが、背面バスレフと違って壁に吸収されることを期待できないため、設計も難しくなる。天面バスレフや底面バスレフや側面バスレフも作れるし、筒をキャビネット内部でなく(多くの場合煙突状に)外に出すこともできるが、市販品ではあまり一般的でない。ポートをホーン状にしてさらに癖をつけたものもある。
バスレフは空気ばねを利用した共鳴装置だが、これを機械的なばね(というか、ダミーのスピーカユニットのような部品)に置き換えたものをドロンコーンとかパッシブラジエータと呼ぶ。空気の容量ではなく振動部分の重さなどで共鳴周波数を決められるのが特徴だが、バスレフよりも機械的に複雑になる。ダブルバスレフは、通常のバスレフが箱>筒>外となっているのに対し、箱>筒>箱>筒>外と2段階にバスレフを設けた形。特性を複雑にコントロールできるが設計が難しくサイズも大きくなりがち。通常のバスレフも含め、位相反転式は音の立ち上がりや制動が遅くなる(途中にばねがある以上構造的に避けられない)が、ばねの数やスピーカユニットからポート出口までの筒の長さが増える分、面倒も増えるのだろうと思う(多分)。
ダブルバスレフは次数が高いハイパスフィルタと解釈できるが、サブウーファーなどではこれをローパス+ハイパスの形にしたバンドパス様タイプもあり、密閉エンクロージャにバスレフエンクロージャを被せたような実装(4次フィルタになる:ケルトン式ともいい、いわゆるASW型はこれとホーン式の中間的な)やケルトン式の背面(というか第一キャビネット)にも外に通じるポートを設けた前後バスレフ(6次フィルタになる:普通のバスレフポートを前と後ろに出したのとは異なり、第一キャビネットと第二キャビネットの両方にポートを設け、それを両方外部に出している)などがある。
フロントロードホーンは、密閉型のユニット取り付け部分をラッパ状にしたもの。空気を押す面積を大きくすることで音響インピーダンスを上げ、効率を上げる。癖が出やすくサイズもかなり大きくなるので一般家庭ではほとんど使われず、効率が重要なPAスピーカに用いられることが多い。。コンビネーションホーンは、フロントロードホーンとバスレフやバックロードホーンを組み合わせたもの。効率はさらに高まるが、サイズが非常に大きくなるので、PAの中でも映画館など大規模な固定会場でしか使わない。
ちなみに、スピーカユニットの性能テストなどでは、IEC 60268-5のTYPE A(94×124×64cmの密閉型600Lで、日本で古くから使われていたJIS標準箱が元になったそうな)とTYPE B(約450Lの台形密閉型)使われることが多い。
各楽器の音域と特性のページで少し触れたが、人間の声帯から口唇までがなす共鳴管の固有周波数は男性で約500Hz、外耳道がなす共鳴管の固有周波数は約3KHz(インピーダンスとしては「長さ28mmで一様断面50.3mm^2の音響管」とよく近似するらしい:信州大学工学部電気電子工学科の資料より)、声の個性の判別は主に倍音成分を聞き分けているらしい(どちらも閉管扱い)。
もちろん、単純に管の長さだけで説明できる特性だけでなく、もっといろいろな要素が複雑に絡み合って聴覚を形成しているのだが、そのうちの1つに興味深いものがあったので紹介したい。耳音響放射(OAE:OtoAcoustic Emissions)という現象が起こっているという説が、他のページにも何度か登場したRGWオンラインドラム講座で紹介されている(該当記事)。内有毛(マイクに相当)で受け取った音波が外有毛によって再生され、それをまた内有毛が受け取ることでフィードバック回路のような働きになるということのようだ(レイテンシは3~20msで、低音ほど長いらしい)。
さらに、この機能の誤動作(バグというより仕様に近い振る舞いだが)によって歪成分耳音響放射(DPOAE:Distortion Product OAE)という現象も起こり、これは周波数f1とf2(f1<f2)の2音を同時に聴くとf3=2*f1-f2となる音が耳の中で勝手に発生する(mとnを整数としてf3=m*f1+-n*f2というのが本来らしい:音が出る仕組みのページで紹介した音程根音は物理学的な作用だが、こちらは生理学的な機能)というもの。すでに臨床試験で有効性が確認され、聴覚検査機器などに応用されている(九州大学医学部耳鼻咽喉科のサイトに解説がある:トップ)。もとは、外からの音が途切れているのに耳の内部からの音だけが鳴りつづける誘発耳音響放射(TEOAE:Transiently Evoked OAE)という現象を測定していたようだが、それだと効率が悪いので歪成分耳音響放射が発明されたようだ。
当然、脳を中心とした神経系でも相当の補正があるので、これだけで人間の聴覚を把握することはできないのだが、低音は聴覚上アタックタイムが伸びる(打ち込みについてのページでも触れたが、20msというと結構な長さである)とか、パワーコードを聴くと耳の中で基底音の1オクターブ下の音が勝手に鳴るといったことは、覚えておいて損はないだろう。
筆者もよくわかっていないのだが、できるかぎりの情報を示す。
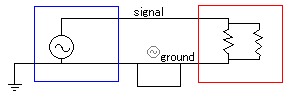
まず、アンバランス伝送で考える。
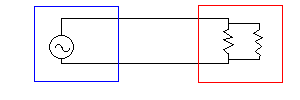
こうやってただつないだだけだと、送信側の機器(青)と受信側の機器(赤)に電位差があった場合(というか、電位差がまったくゼロということはありえない)に回路に電流が流れ、悪影響が出る(電位差の大きさにもよるが、コンデンサが想定どおりの動きをしないとか、逆電流で部品が損傷するとか)。ただし、漏電でもしていない限り大電流が流れることはないので、このつなぎ方だから即音が悪くなるというわけではない(反対にいうと、1つの機材が漏電したときに他の機材を巻き込みやすいつなぎ方ではある)。
回路の一部にループができると、その部分がループアンテナ(導線で環を作ってバイアスをかけてやると、電界や磁界の変化を検出できる:本当はアンテナとケーブルのインピーダンスマッチングなどがあって面倒なのだが、筆者は理解していない)のような役割を果たして、余計な信号(つまりノイズ)源になる。
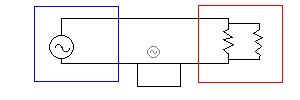
20KHzの電波でも波長は15kmくらいなので、ごく小さなループならあまり気にしなくてもよい(はず)。また、ループ部分がなす面積も影響するようで、2本の線をぴったり寄り添わせれば電界の影響を抑えられるし、もっと手の込んだことをするなら縒り線にしてしまえば、磁界の影響(と、ついでにケーブルから出るノイズ)もかなり抑えられる。
ここで導線の片方をアースしてやると、機器間の電位差電流やらループからのノイズやらはアースの方に流れてくれる。また、上の図では回路全体が大きなループを作っているが、一端をアースしたことでそれも解消されている。
ただし、アース抵抗が0Ωであれば余計な電流がすべてアース行きになるのだが、実際にはいくらかの抵抗がある。保護接地(洗濯機用のコンセントなどについている、漏電などに備えた安全対策用のもの)の場合、300V以下の機械器具の外箱用であるD種接地工事で100Ω(遮断装置つきなら500Ω)以下と定められているが、音響機器のノイズ対策だと、たとえば600Ω回路でも数Ω~数十Ωくらいのオーダーが要求されそうに思える(地質などの影響で、100Ω以下のアース施工はプロでも相当難しい場合があるらしい:具体的な数字については後でまた少し触れる)。ちなみに、グランドの回路がループしている部分をグランドループ(アースの場合はアースループ)という。
アースがしっかりと確保できれば、グランドにいくらノイズが入っても(理論上は)信号の伝送に影響が出ないため、グランドの導線をシールド(信号線の代わりに電界ノイズを引き受けて守る部分)と兼用にすることがほとんどである。結局、磁界ノイズは縒り線で、電界ノイズはアースされたシールドで防ぐということになる。シールドは電界ノイズを積極的に引き受ける仕組みなので、オーディオで使うような周波数域では、シールドをアースしないと上から2番目の図と同じ状態になってノイズが増える(はず)。前述の通り機器間の電位差もグランドラインで逃がしてやればよく、グランドをシャーシに落とすこともしくはシャーシ電位をアースに落とすこと(グランドがアースに落ちていればどちらも同義だが)をシャーシアースとかフレームアースなどという(キャノンコネクタには、シャーシとメスコネクタのシェルが接触し、シェルがグランドとつながる仕組みを備えたものもある:シャーシ電位とグランド電位を意図的に分離している製品もあるため、最近は、コネクタ内部で結線しない限り接続されない製品がほとんどのようだ)。機器のシャーシ同士を直接導線でつないでフレームアースを取ることもある。
バランス伝送の場合も、内部ではアンバランスで扱う(例外がないとは言い切れないが、バランスで扱ってもデメリットの方が大きいらしい)ため事情はあまり変わらない。
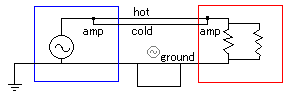
図中にampとあるのは、コールド分だけ位相を反転して通過させるアンプ(トランスを使うものもある:詳しくはその他のページを参照、グランドリフトの話題もそちら)。アンプからアンプまでの間の信号線(ホットとコールドを縒り線にするのが普通:芯線を縒り線で作るという意味ではなく、ツイストペアケーブルを使うという意味)に乗ったノイズは、コモンモード(ホットとコールドに同じノイズが乗る)であればアンプの部分で打ち消される。
アースは1点で行うのが基本で、2点以上でアースを行う(分散アース)と、地面が導線代わりになって非常に大きなアースループができる。
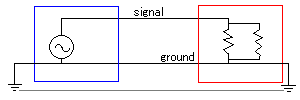
アース地点が十分離れているか、間に何らかの絶縁があれば問題にならないのかもしれないが、普通は避けた方がよい。また、電柱には普通アースがついているが、近くにアース棒を埋め込むと電柱への落雷や柱上トランスの漏電などで電柱>地面>アース棒>アース棒に接続した機器>操作している人と大電流が流れるおそれがあり、安全上問題になる。
2pケーブル2本でステレオ音声をアンバランス伝送したり、3pケーブル2本でステレオ音声をバランス伝送する場合、どうしてもグランドループができる。先にも述べたが、ケーブルが短ければループの長さも短くなるためそれほど神経質になる必要はないと思われる。大規模システムなどでグランドループが問題になる場合は、グランドリフト(2本のケーブルのうち片方のグランドをオープン(未接続)にする)スイッチがついた機材を使えばよいだろう(最初からグランドオープンのケーブルもある)。ケーブルとノイズの関係については、日本舞台音響家協会のサイトにカナレ電気の山口さんという人が寄稿したケーブルのノイズ対策についてという記事が参考になる(アースについても「接地抵抗はなるべく低くする。(例えば1Ω以下)」という言及がある)。大地自体の抵抗については、サンコーシャという(避雷針などを扱っている本気系の)会社が電気学会と電子通信学会による昭和43年3月の原図を加工したものを掲載してくれている。
余談になるが、正しく施工された日本の商用電源100V2極平行コンセント(JIS C 8303)は、左の穴が長辺9mmで中立線(ニュートラル)、右の穴が長辺7mmで電圧線(ライブ)である。アメリカやヨーロッパなどは、中立線と保護接地が最終的に1点でアースされるTNネットワークを採用している(中立線と保護アースの合流方式により、TN-S、TN-C、TN-C-Sの3種類がある)が、日本では中立線と保護接地(自前でアース棒を地面に埋める)を分散アースするTTネットワークが主流なので、中立線の電位と保護アースの電位が異なる場合がある(というか、必ずいくらかは異なる:片方のアースに落雷などで大電流が流れた場合、アースループにもそれなりの電流が流れるため、安全上もあまりよい方式ではない)。また、中立線の電位は(多くの場合電柱からアースされているが、必ずしもそうだとは限らないので)大地電位と同じだとは限らない。
アースが確保できない(ノイズを外に逃がせない)場合は、グランドループなどを避けてノイズを入れない方向で工夫する必要があるだろう。コンセントを差し込む向きによって機器のシャーシ電圧が微妙に変わるため、各機材の極性をそろえることがあるが、素人がやると危険なので、知識と技術がある人以外は手を出すべきでない。
Windowsで広く使われているものに絞り、EASIやOpenAL+OSS or ALSAなどには触れない。Vista以降ではWASAPIも使えるがこれも省略。
筆者はきちんと理解していない事柄なので、正確な情報はMSDNの解説(その1、その2、その3、その4)やcakewalkの解説(その1、その2)を参照。すべて英語のドキュメントだが、筆者が探した限り、日本語の情報にはロクなものが見つからなかった(MSDNの解説その3の日本語訳と思しきページはあった:目次、ドライバの解説1、ドライバの解説2(同内容))。
前提知識として、アプリケーションと直接データをやり取りするAPIには、MME、DirectSound、ASIOなどがある。このうちMMEはWindowsで長年標準的に使用されており、DirectSoundはその代替的な立場、ASIOをサポートするオーディオアプリケーションも多い。普通のアプリケーションはこのインターフェイス部分までしか関知しない(REAPERなど例外はあるが)。
インターフェイス(mmsys.cpl、mmsystem.dll)以降のフローは、WMDのユーザーモードオーディオドライバ(wdmaud.drv)、WMDのカーネルモードモードオーディオドライバ(wdmaud.sys)、Windowsのシステムオーディオドライバ(sysaudio.sys)と渡る。
古いシステムでWMDではなくVxDを使っている場合は、wdmaud.drvではなくdsound.vxdを使うのだと思うが、詳しい情報が探せなかった。
システムオーディオドライバ以降はDirectSoundと同じ流れになるようなので、次の項でまとめて触れる。
インターフェイス(dsound.dll)以降のフローはMMEより単純で、直接sysaudio.sysを叩くだけである。
システムオーディオドライバ以降は、カーネルミキサ(kmixer.sys)を経由してWMDのPort Classドライバ、Stream Classドライバ、AVStreamドライバなどに渡される(それぞれportcls.sys、stream.sys、ks.sysが該当ファイルのようだ:クラスドライバモデルという枠組みで実装されている)。cakewalkの図だとこの段落の処理からが「WMD Kernel Streaming Interfaceの下」になる。
クラスドライバの下位にはハードウェアベンダーが実装したミニドライバがあり、port driverの下位ドライバであればmini-port driverなどといった呼び方をする。ハードウェアベンダーはクラスドライバのインターフェイスに合わせてミニドライバを実装するだけでよく、それよりも上位のドライバについて関知する必要はない(はず)。
cakewalkの図にあるAECというkmixer.sysを迂回する経路については詳細がわからなかった(多分ベンダーカスタムのミキサーデバイスではないかと思う)。
ASIOインターフェイスを提供するユーザーモードドライバの下位にカーネルモードモジュールがあり、その下にハードウェアの抽象化を行うレイヤーがある。
多分、カーネルモードモジュールがWMDでいうKernel Streaming Interface以下に相当する処理を行うのだと思うが、サンプルレート変換やミキシングなど複雑な処理は省いてあるため、この部分でパフォーマンスに差が出るのだろう。
ASIOの仕様書を読んだわけではないので確かではないが、cakewalkの図だとミニドライバのレイヤーまで入り込んでいるように見えるし、ハードウェア抽象化のレイヤーはASIO規格の範囲外であるようにも見える(図を簡略化しただけかもしれない)。
ASIOのAPIを提供するので、アプリケーションからは単なるASIOドライバに見える。本体はasio4all.dllというユーザーモードドライバで、下位ドライバにASIOのカーネルモードモジュールではなくカーネルストリーミング(多分クラスドライバを叩いているのではないかと思うのだが未確認)を使っているのが他のASIOドライバとの違い。
結局カーネルストリーミングにASIOのインターフェースを被せるだけのソフトであって、性能的にも似たようなもの。ただし、手作業でやると面倒な処理を任せられる分、限界性能では素のカーネルストリーミングに微妙に劣る(実用上問題になるような差ではない)。
ASIO2KSやAxASIOなども似たような実装ではないかと思う(Windows版Audacityを使った実際の作業コーナーのAudacity以外のDTMソフトのページも参照)。
オーディオ機器のインピーダンスは600Ωのものが多い(昔の電話機に合わせて統一したらしい)。600Ω以外では、ラインの入力インピーダンスで10~25KΩ、マイクの入力インピーダンスで1~10KΩ、エレキギター直結用の入力インピーダンスで1MΩ前後、スピーカの入力インピーダンスで数Ω、ラインの出力インピーダンスで1KΩ前後、マイクの出力インピーダンスで数百~1000Ω(ものにより数KΩ)、アンプの出力インピーダンスで10Ω前後、ヘッドフォン用の出力インピーダンスで数十Ω(ハイインピーダンス対応品は1KΩ前後)、ギター/ベース用のマグネティックピックアップ(パッシブタイプ)の直流抵抗で5~30KΩ、数千円~1万円クラスのシールド線(バランス)で10~数十Ω/km@20℃(ちなみに静電容量は数十~100PF/m@1KHz)、Dsub25を使ったバランス伝送で110Ω、といったものが多い(多いだけ)。マイクをギター用のインプットにつなぐことはたいてい可能だが、インピーダンスの問題をクリアしても出力レベルが違う(普通マイクの方が小さい)ので、うまく機能しない場合がある。
マイク・スピーカ・ヘッドフォンに使用される磁石は、アルニコ磁石・フェライト磁石・サマリウムコバルト磁石・ネオジム磁石がほとんど。アルニコ磁石はアルミとニッケルとコバルトが原料(安易なネーミングだ)で、エレキギター用のピックアップやアンティークタイプの機器に使われる。フェライト磁石は酸化鉄を焼結したもので、黒板や冷蔵庫にくっつくマグネットなどいわゆる普通の磁石。サマリウムコバルト磁石は名前のまんまサマリウムとコバルトが原料で、磁力の強さがウリだったが、ネオジム磁石の登場でさびないことと温度特性(200℃くらいでも使えるそうな)くらいしか取り柄がなくなった。ネオジム磁石(さびやすいので普通メッキしてある)はネオジム(俗称でネオジウムとかネオジとも)と鉄が材料で、非常に磁力が強く価格もサマリウムコバルト磁石より安い(ハードディスクの中に入っているやたらと強力な磁石はたいていこれ)。
測定について。真面目にやろうとするとどうしてもお金がかかるが、最近は業務用のものと比べて1桁以上安い(といっても一般人に手が出る価格ではなかったりするが)簡易測定セットのようなものも売られており、audiomaticaのCLIOやLiberty Instrumentsのpraxisなどが人気のようだ(伝聞)。特殊な条件をそろえて限定的な測定をする単品ソフトウェアはさらに安価で、FESBのARTAやAudio RightmarkのRMAAなどがある。いづれも、原理を理解してしっかりセッティングしないと無意味だが、自信とお金がある人は挑戦してみても悪くないかもしれない。追記:無料のソフトだとSpeaker Workshop(sourceforgeのプロジェクトページ、かつのへやというサイトの紹介記事)が有名なようだ。